Что такое веб-архив и как им пользоваться
Содержание:
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Всемирный веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
Бесплатные способы восстановления
Ручной
Собственно основной ресурс, который используют все сервисы для восстановления сайта это https://archive.org/web/
Ниже отображается календарь за выбранный год, там вы можете увидеть конкретный месяц и день, когда был произведен снимок.
Кликайте по снимку, откроется окно со страницей сайта за тот день. Открываете консоль разработчика и копируете html и все ресурсы необходимые странице — картинки, css, js и др. Неблагодарное дело.
Аналоги archive.org
https://archive.org/web/ не единственый проект, который делает снимки сайтов и хранит их. Существуют и другие напримерArchive.ishttp://timetravel.mementoweb.org/ уникальный проект, своего рода гугл по сайтам-аналогам archive.org
Веб кэш
Если нужно восстановить данные сайта, которые были потеряны недавно, может подойти кэш поисковой системы Гугл. Можно попробовать тут https://thisis-blog.ru/posmotret-sajt-v-keshe/
Библиотеки
Можно развернуть и свою поделку под свои нужды, если есть возможность. На гитхабе ищется по ключу wayback-machine
Что там можно найти, примеры:
https://pypi.org/project/wayback-scraper/https://github.com/sangaline/wayback-machine-scraperhttps://github.com/hartator/wayback-machine-downloader
Делитесь своим опытом использования данных сервисов. Если нашли ошибку, либо есть что добавить, тоже пишите.

Best Internet Wayback Machine Alternative
Let us begin…
Contents
ScreenShots is the another best alternative to the Wayback machine. As its name it works, screenshots just take a snapshot of the websites and save it to the database so you can only access the snapshot. You can not access the code and other things like its destination link and more.
Features:
- Captures screenshots instead of copying domain code
- Easy to use Interface
- Shows complete WHOIS record of the domain ID
Archive.is is one of the best Wayback machine alternatives. The archive comes with great functionality which can not offer others. The archive is getting so much popularity on the internet because of its function, user-friendly and easy navigation. When you visit Archive.is you find two search bar. Archive.is gives you the power to access the content of any websites and also the screenshots of that website.
Features:
- Archives the screenshot and code of a web page
- Has an enormous database
- Allows you to share & download results
- You can archive any website, anytime
iTools is also a certain website and provides you all the information of any domain name. This site accesses the Alexa database. It will also tell you the domain popularity, traffic, and competitors of the website.
iTools is a slightly different tool from other wayback machine tools in the list as it doesn’t provide any archive option on its homepage. However, you can access it in another way, and to do that, you first need to click the “Internet” tab from its homepage and then on “Website” you need to check the archive for. It also shows you everything important about your competitor to help boost your business.
Features:
- Shows up all information related to domain
- Used to boost your business

Features:
- Shows up detailed information of a domain
- Display transparent results related to your competitor
This site offers you lots of functionality; you can use this to extend your business. You can also use archive content of the website also, and this helps you see your competitors. Moreover, you do not need any special skills. You just need to sign in and get started.
Features:
- Has Online Marketing Tools
- Let’s you archive website content
Editor’s Recommended Alternatives
- Best Dropbox Alternative
- Best Free Game like Minecraft
- Best VLC Alternative
- Best Clash of Clans Alternatives Games
- Best Kindle Alternative eBook Readers
Conclusion
So, readers, These are the Best Wayback Machine Alternative Sites, totally trusted and working so you can use any of them. With the help of these sites, you can check the site history, content and how a website look in past or any deleted content also you can access. If you find any other site better than these, let’s know through comment section.
Edited By: Abhiyanshu Satvat
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.

Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.

Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
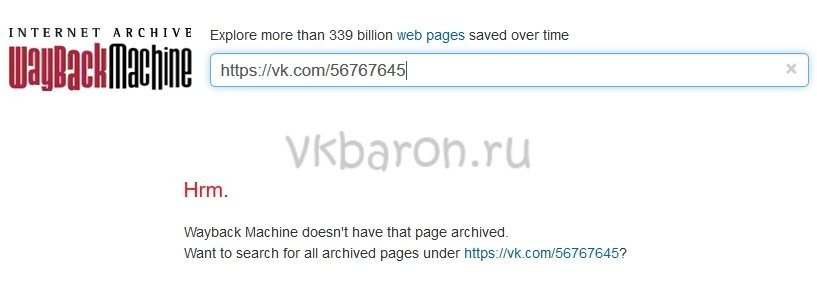
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Оцифрованные документы других стран
Сайт мормонов
Помимо этого, существует сайт мормонов, где размещено огромное количество документов из стран:
- Австрия,
- Албания,
- Англия,
- Армения,
- Беларусь,
- Бельгия,
- Венгрия,
- Германия,
- Грузия,
- Дания,
- Испания,
- Казахстан,
- Киргизстан,
- Латвия,
- Литва,
- Молдова,
- Польша,
- Словакия,
- США.
- Украина,
- Эстония,
(Документы из России, кстати, там тоже есть)
По каждому государству представлены различные генеалогические источники из их архивов, которые делают онлайн поиск в архивах крайне простым.
Сайт называется familysearch.org. Он заблокирован в России. Документы с него можно найти в группах генеалогов Вконтакте, а на форуме ВГД оставляют ссылки на облачные хранилища.
Благодаря большой работе, проведенной архивами и волонтерами любому человеку доступен онлайн поиск в архивах его предков.
Сайт ancestry
ancestry.com — сайт, который содержит генеалогические документы, семейные древа США и еще 9 стран. Кроме того, там частично находятся генеалогические сведения и других стран. Возможен поиск по фамилиям и территориям.
WorldCat
worldcat.org — крупнейшая база данных ,содержащая более 200 миллионов книжных изданий, описания произведений. В ней можно найти некоторые метрические книги.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
IT-специалист и продвинутый пользователь ВК. Зарегистрировался в соцсети в 2007 году.
r-tools.org

Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Что необходимо учитывать при поисках по фамилии из архива
Если искомый вами человек не занимал каких-либо высоких должностей и не прославился какими-либо делами, то не стоит думать, что данных о нём вы не найдёте. Практически о каждом человеке имеются сведения в государственных архивах. В последние попадают различные документы о рядовых событиях нашей жизни – записи о рождении и смерти, получении образования, информация о покупке и продаже недвижимости, справки нотариусов и многое другое. По всему этому вороху документов можно не только получить базовые данные об искомом человеке, но и иногда составить довольное обстоятельное описание его жизненного пути.
Запаситесь вашим свидетельством о рождении. Если вы будете обращаться в ЗАГС, вам будет необходимо подтвердить своё родство с искомыми вами родственниками. В этом и поможет упомянутый документ. Архивные документы умерших выдаются ЗАГСами бесплатно только их родственникам.

Ищите различные варианты фамилии нужного человека с опечатками и ошибками. Как известно, далеко не всегда документы пишут грамотные люди. А особенно, когда дело касалось боевых документов по отдельным частям и подразделениям. Потому пробуйте различные варианты искомой фамилии, пишите, как она слышится (например, вместо «Петров» попробуйте «Питров»). И, возможно, вам улыбнётся удача.

В данном документе вместо «Божков» написали «Бажков»
Также рекомендуем регистрироваться на интернет-порталах баз данных. Зарегистрированные пользователи получают больше возможностей для осуществления поисков.
Как посмотреть архивные копии страницы в web archive
Откройте сайт Web Archive или приложение сервиса. Если используете последнее, сразу после запуска создайте аккаунт.
Вставьте ссылку на нужную страницу и нажмите Enter (на сайте) или Overview of All Archives (в приложении).
Пролистайте календарь, чтобы найти подходящие копии. Дни, в которые бот создавал дубликаты страницы, отмечены кружками.
Нажмите на подходящую дату, чтобы просмотреть архивную копию.
Сайт также позволяет сравнивать две копии. Для этого на странице с календарём нажмите Changes, отметьте две даты и кликните Compare.
В результате Web Archive отобразит копии рядом и выделит несовпадения.
Зачем нужна АИС?
АИС — автоматическая информационная система, которая позволяет зарегистрированному пользователю просматривать описи фондов и архивные документы, сидя за компьютером в читальном зале и дома.
 Главная страница АИС Новгородских архивов. Онлайн поиск в архивах бесплатный
Главная страница АИС Новгородских архивов. Онлайн поиск в архивах бесплатный
Объем доступных документов и
стоимость зависит от архива. Часть архивов предоставила полностью бесплатный
доступ, другие просят оплату за просмотре каждого дела или время просмотра
(день, неделя без ограничения количества дел). Подробности указаны обычно на
сайте.
Но даже платная функция экономит не только ваш бюджет, если вы живёте в другом городе, но и время на поездки.
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

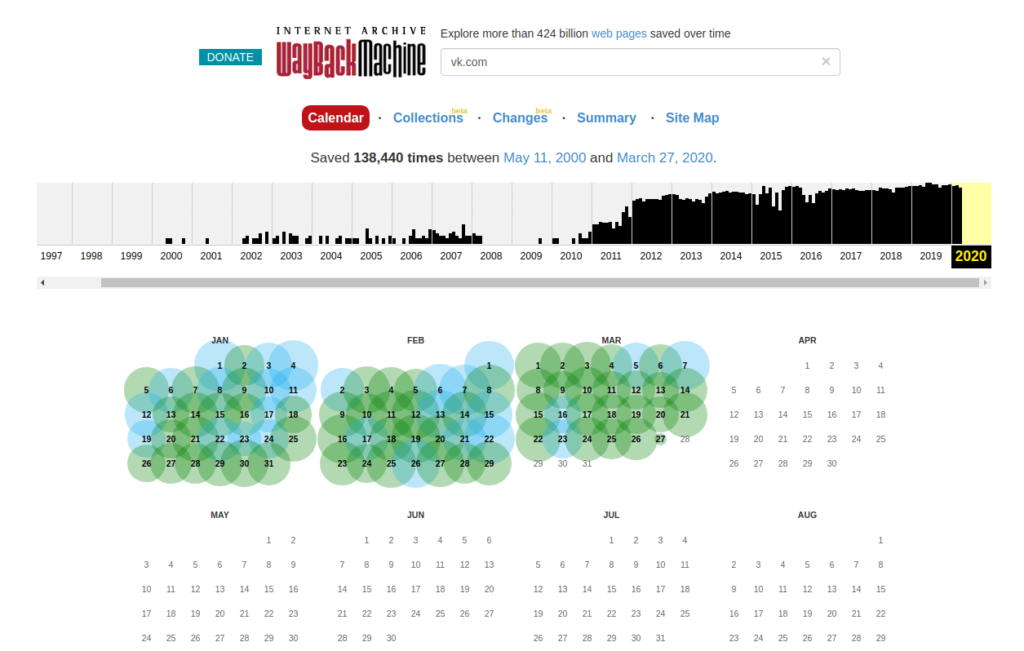
График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
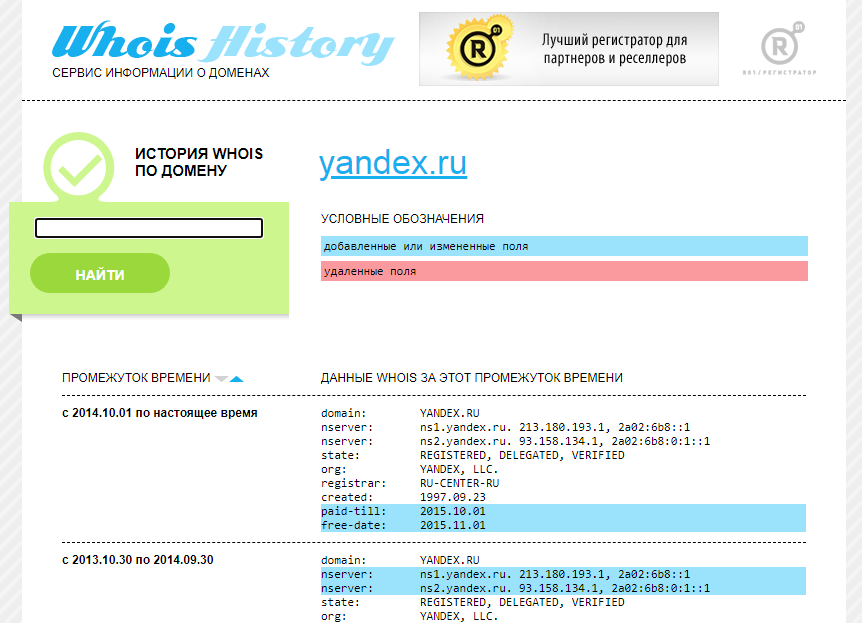
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Перечень ссылок на АИС региональных архивов
| Региональный архив с указанием ссылки на АИС или иных сайтов с документами |
| Астраханская область rodoslovnaya.astrobl.ru |
| Башкортостан edoclib.gasrb.ru |
| Бийск ais.biysk22.ru |
| Вологодской области https://gosarchive.gov35.ru/archive |
| Воронежской области www.arsvo.ru/vhod-v-ais/ |
| Государственный архив Российской Федерации statearchive.ru/384 |
| Дагестан www.cgard.ru/af/index.php |
| Иваново (https://yadi.sk/i/-We1SshD3NdGQU) |
| Калининградская область gako.name/elektronnyy-arkhiv/ |
| Кировская область База ИР и МК gako-kirov.ru/index.php/bd.html |
| Костромская область chitalnyj-zal.kosarchive.ru/login/ |
| Краснодарский край (АИС есть, но доступ только в читальном зале) Опись фондов тут kubgosarhiv.ru/fonds/putevod.php |
| Красноярский край красноярские-архивы.рф/about/informatizatsiya/167 |
| Курская область http://archive.rkursk.ru/node/746 |
| Московская область (ЦГАМО) gaumo.kaisa.ru:8186/ |
| Мурманская область aisdafmo.gov-murman.ru:8084 |
| Новгородская область (ГАНО, ГАНИНО) gano.altsoft.spb.ru |
| Новосибирская область e-archive.nso.ru |
| Оренбургский архив Сайт архива archives.orb.ru; Документы выкладывают тут https://vk.com/albums-163258126 |
| Пензенская область АИС arhiv-pnz.ru/page/3244 |
| Пермского края Опись фондов catalog.archive.perm.ru ;сайт Поколения Пермский край pokolenia.permkrai.ru; сайт zz-project.ru |
| Псковская область document.archive.pskov.ru/orders/login.zul |
| Республика Саха (Якутия) 91.201.237.48:81/Default.aspx?ReturnUrl=%2f |
| Российский государственный архив древних актов АИС есть, доступ в читальном зале. Описи доступны онлайн rgada.info/poisk/index.php?B1&fund_name=&fund_number=350&list_name=&list_number=&Sk=30 |
| Российский государственный военно-исторический архив бд.ргвиа.рф |
| Российский государственный исторический архив Дальнего Востока catalog.rgiadv.ru/ |
| Самарская область cgaso.regsamarh.ru/Default.aspx?ReturnUrl=%2f |
| Санкт-Петербург архивы spbarchives.ru |
| Свердловской области (АИС: uralarchives.ru/index.php?page=enter сайт «Регистр населения Урала» urappdata-urgi.urfu.ru/ural-population-project) |
| Татарстан arhiv.tatarstan.ru/eais.htm |
| Тобольск tobarhiv.72to.ru |
| Томская область (опись фондов archtomsk.tomica.ru/) |
| Тульская область gato.tularegion.ru/ |
| Тюменская область archiv.72to.ru/index.php/gosudarstvennyj-arkhiv-tyumenskoj-oblasti/materialy-arxiva |
| Удмуртия gasur.ru/databases/ |
| Хабаровский край АИС: eaishk.ru |
| Ханты-Мансийский автономный округ (АИС: архивы-югры.рф) |
| Центральный государственный архив Москва (есть отдельный сайт с описями kraevedmo.ru) |
| Челябинской области АИС: ais.archive74.ru/а также документы на сайте edoclib.gasrb.ru бесплатно) |
| Чувашской республики (опись фондов giachr.kaisa.ru) |
| Ярославской области ais.yararchive.ru/Default.aspx?ReturnUrl=%2f |
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Особенности поиска сведений о человеке
Прежде чем непосредственно перейти к поиску данных, необходимо определиться с той информацией, которая нам о нём известна.
Она может состоять из следующих составляющих:
- Фамилия, имя, отчество. Если это женщина – её девичья фамилия до выхода замуж;
- Дата рождения, включающая число, месяц, год. Если такие данные неизвестны – приблизительный временный период рождения человека (несколько лет);
- Место крещения;
- Место рождения – страна, область, район, город, село, посёлок, губерния, волость, улица, дом и так далее;
- Место жительства;
- Национальность;
- Вероисповедание;
- Сословие (до революции) – дворянство, духовенство, казачество, мещанство, крестьянство и другие;
- Титул, звание, чин;
- Семейное положение (брак, венчание);
- Место службы;
- Образование – университет, факультет, специальность, школа, лицей и так далее;
- Владение недвижимостью, место расположения недвижимости.
Определитесь, какие документы по перечисленным данным имеются у вас на данный момент, и можете ли вы при необходимости предоставить их копии. Систематизируйте их по полочкам, поймите, что вам уже известно, и в каких конкретно сведениях вы нуждаетесь на данный момент.

Если искомый – ваш родственник, опросите всех членов вашей семьи на предмет сведений о нём. Когда он родился, были ли у него ещё родные, где учился, женился, работал и другое. Есть ли у них какие-либо документы о нём, и если есть – попросите их на время или сделайте их копии. Это поможет в процессе поиска нужного человека и составления личного архива.

Лучше всего формировать базу данных на компьютере. Это поможет вам легко находить и использовать имеющуюся информацию. В случае бумажных документов рекомендуем создать удобную картотеку, чтобы быстро находить нужную бумагу.
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
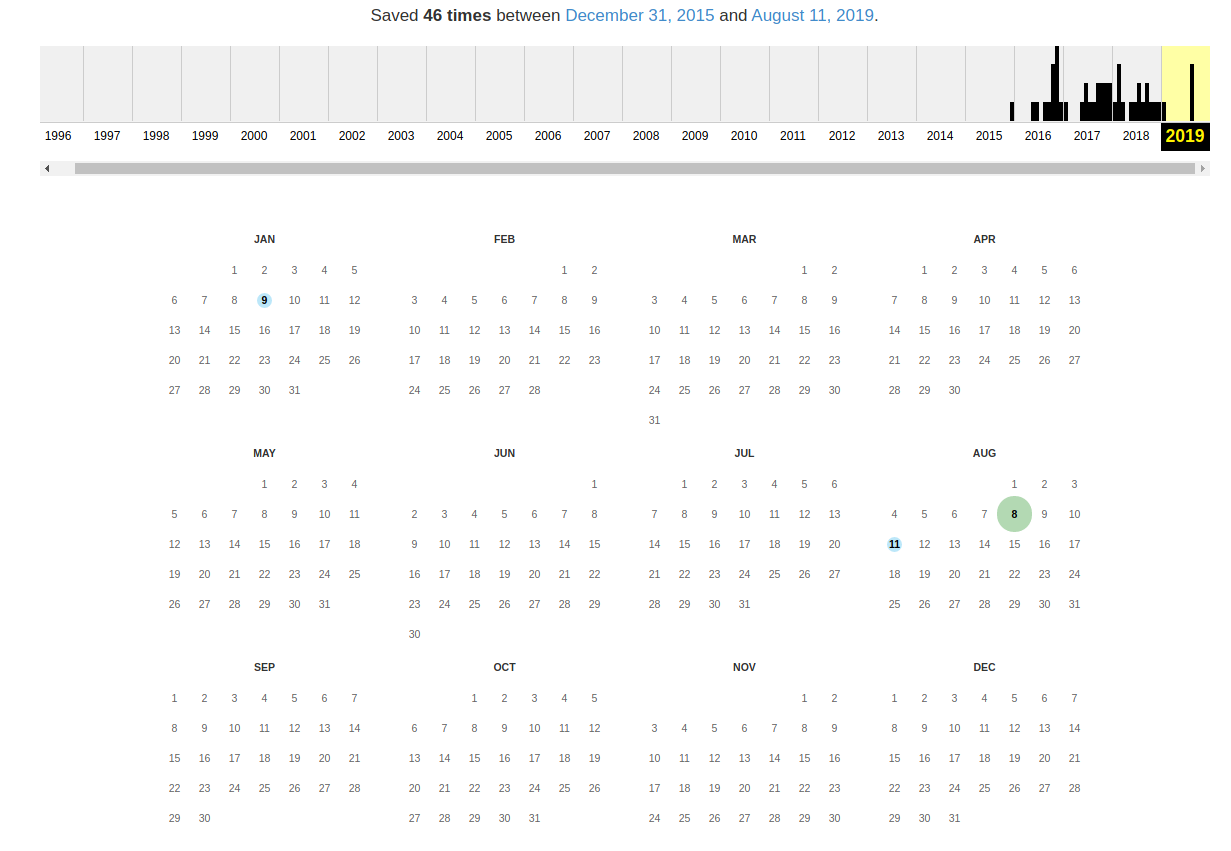
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
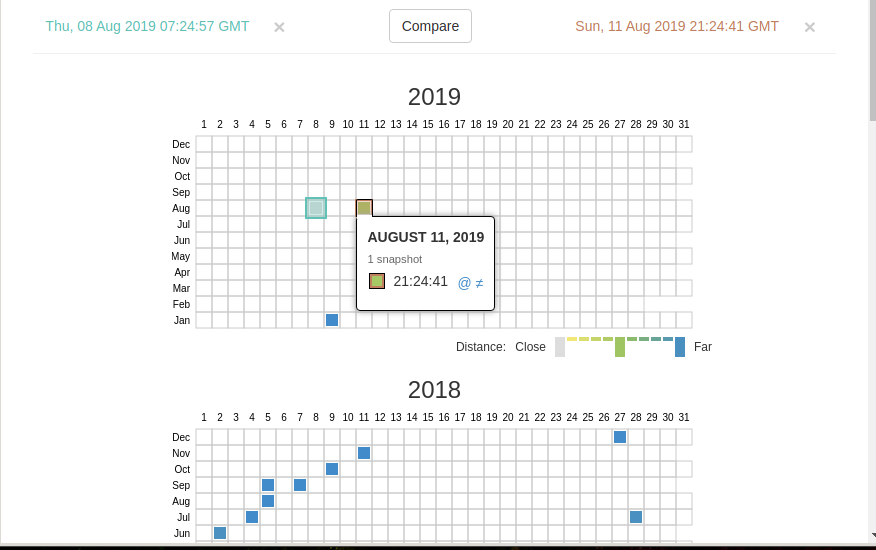
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
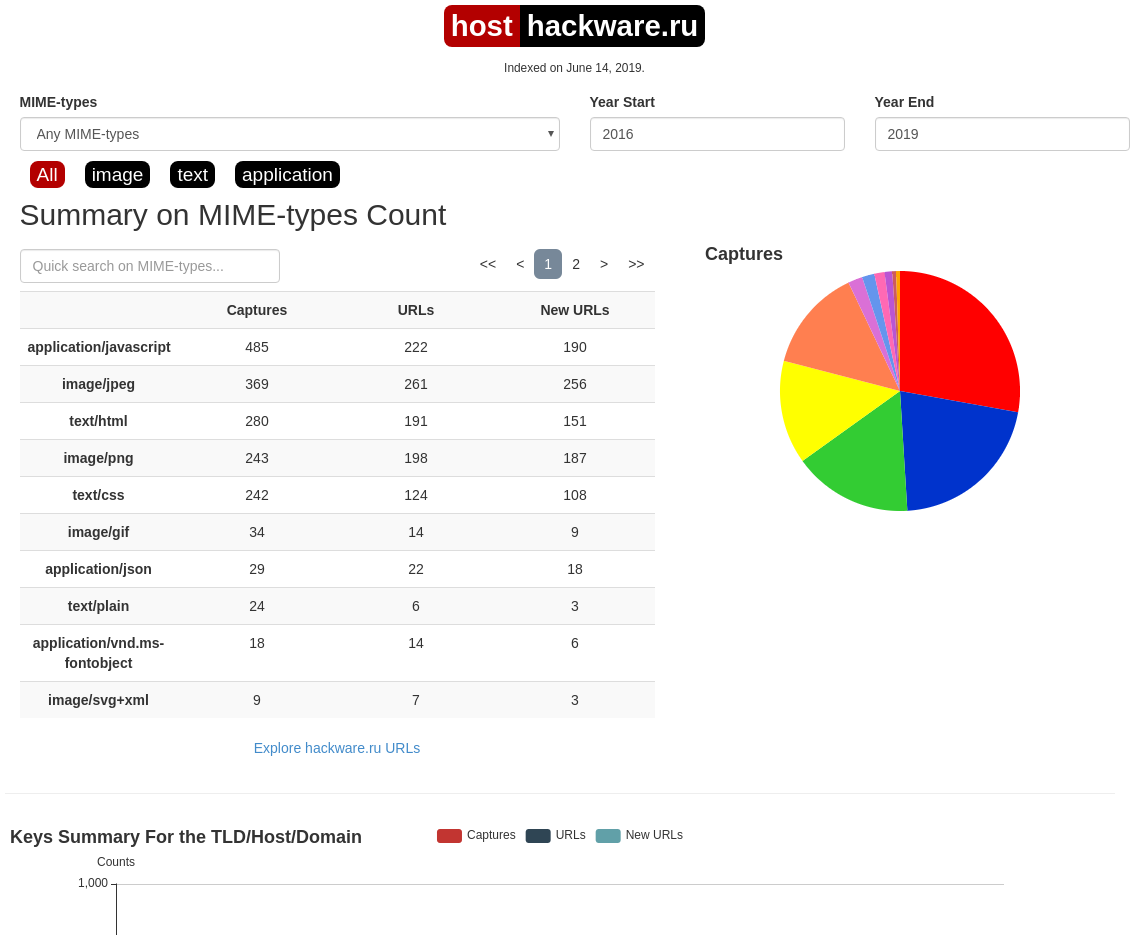
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.
В каких бесплатных архивах стоит искать человека по ФИО
В первую очередь обращайтесь в архивы по месту проживания или работы искомого вами человека. Начинайте с ведущего архива данного региона (области) – Центрального государственного архива города Москвы, Московской области, Краснодарского края и так далее.

Позвоните в свой региональный архив, посетите его страницы в сети Интернет, свяжитесь с ним через е-мейл или мессенджеры (при возможности). Узнайте каковы особенности отправления запросов в данные архивы, как долго необходимо ждать ответа, какие сведения они предоставят, и на каких условиях. Подавайте запрос и ждите ответа (в некоторых бесплатных случаях он может затянуться).
Если в центральных архивах ничего нет, переходите на местный (локальный) уровень. Делайте запросы в местные архивы, в ЗАГСы (в последних часто можно найти записи об искомых нами людях).

mydrop.io
(реф. ссылка)
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления