Haswell: обзор, преимущества и особенности процессоров
Содержание:
Added instructions[edit]
AVX2 — Integer data types were extended to 256-bit SIMD.
- VBROADCASTI128
- VBROADCASTSD
- VBROADCASTSS
- VEXTRACTI128
- VGATHERDPD
- VGATHERDPS
- VGATHERQPD
- VGATHERQPS
- VINSERTI128
- VMOVNTDQA
- VMPSADBW
- VPABSB
- VPABSD
- VPABSW
- VPACKSSDW
- VPACKSSWB
- VPACKUSDW
- VPACKUSWB
- VPADDB
- VPADDD
- VPADDQ
- VPADDSB
- VPADDSW
- VPADDUSB
- VPADDUSW
- VPADDW
- VPALIGNR
- VPAND
- VPANDN
- VPAVGB
- VPAVGW
- VPBLENDD
- VPBLENDVB
- VPBLENDW
- VPBROADCASTB
- VPBROADCASTD
- VPBROADCASTQ
- VPBROADCASTW
- VPCMPEQB
- VPCMPEQD
- VPCMPEQQ
- VPCMPEQW
- VPCMPGTB
- VPCMPGTD
- VPCMPGTQ
- VPCMPGTW
- VPERM2I128
- VPERMD
- VPERMPD
- VPERMPS
- VPERMQ
- VPGATHERDD
- VPGATHERDQ
- VPGATHERQD
- VPGATHERQQ
- VPHADDD
- VPHADDSW
- VPHADDW
- VPHSUBD
- VPHSUBSW
- VPHSUBW
- VPMADDUBSW
- VPMADDWD
- VPMASKMOVD
- VPMASKMOVQ
- VPMAXSB
- VPMAXSD
- VPMAXSW
- VPMAXUB
- VPMAXUD
- VPMAXUW
- VPMINSB
- VPMINSD
- VPMINSW
- VPMINUB
- VPMINUD
- VPMINUW
- VPMOVMSKB
- VPMOVSXBD
- VPMOVSXBQ
- VPMOVSXBW
- VPMOVSXDQ
- VPMOVSXWD
- VPMOVSXWQ
- VPMOVZXBD
- VPMOVZXBQ
- VPMOVZXBW
- VPMOVZXDQ
- VPMOVZXWD
- VPMOVZXWQ
- VPMULDQ
- VPMULHRSW
- VPMULHUW
- VPMULHW
- VPMULLD
- VPMULLW
- VPMULUDQ
- VPOR
- VPSADBW
- VPSHUFB
- VPSHUFD
- VPSHUFHW
- VPSHUFLW
- VPSIGNB
- VPSIGND
- VPSIGNW
- VPSLLD
- VPSLLDQ
- VPSLLQ
- VPSLLVD
- VPSLLVQ
- VPSLLW
- VPSRAD
- VPSRAVD
- VPSRAW
- VPSRLD
- VPSRLDQ
- VPSRLQ
- VPSRLVD
- VPSRLVQ
- VPSRLW
- VPSUBB
- VPSUBD
- VPSUBQ
- VPSUBSB
- VPSUBSW
- VPSUBUSB
- VPSUBUSW
- VPSUBW
- VPUNPCKHBW
- VPUNPCKHDQ
- VPUNPCKHQDQ
- VPUNPCKHWD
- VPUNPCKLBW
- VPUNPCKLDQ
- VPUNPCKLQDQ
- VPUNPCKLWD
- VPXOR
BMI1 / BMI2 — Bit Manipulation Instructions Sets
- ANDN
- BEXTR
- BLSI
- BLSMSK
- BLSR
- BZHI
- LZCNT
- MULX
- PDEP
- PEXT
- POPCNT
- RORX
- SARX
- SHLX
- SHRX
- TZCNT
FMA3 — Fused Multiply-Add instructions, 3 operands
- VFMADD123PD
- VFMADD123PS
- VFMADD123SD
- VFMADD123SS
- VFMADD132PD
- VFMADD132PS
- VFMADD132SD
- VFMADD132SS
- VFMADD213PD
- VFMADD213PS
- VFMADD213SD
- VFMADD213SS
- VFMADD231PD
- VFMADD231PS
- VFMADD231SD
- VFMADD231SS
- VFMADD312PD
- VFMADD312PS
- VFMADD312SD
- VFMADD312SS
- VFMADD321PD
- VFMADD321PS
- VFMADD321SD
- VFMADD321SS
- VFMADDSUB123PD
- VFMADDSUB123PS
- VFMADDSUB132PD
- VFMADDSUB132PS
- VFMADDSUB213PD
- VFMADDSUB213PS
- VFMADDSUB231PD
- VFMADDSUB231PS
- VFMADDSUB312PD
- VFMADDSUB312PS
- VFMADDSUB321PD
- VFMADDSUB321PS
- VFMSUB123PD
- VFMSUB123PS
- VFMSUB123SD
- VFMSUB123SS
- VFMSUB132PD
- VFMSUB132PS
- VFMSUB132SD
- VFMSUB132SS
- VFMSUB213PD
- VFMSUB213PS
- VFMSUB213SD
- VFMSUB213SS
- VFMSUB231PD
- VFMSUB231PS
- VFMSUB231SD
- VFMSUB231SS
- VFMSUB312PD
- VFMSUB312PS
- VFMSUB312SD
- VFMSUB312SS
- VFMSUB321PD
- VFMSUB321PS
- VFMSUB321SD
- VFMSUB321SS
- VFMSUBADD123PD
- VFMSUBADD123PS
- VFMSUBADD132PD
- VFMSUBADD132PS
- VFMSUBADD213PD
- VFMSUBADD213PS
- VFMSUBADD231PD
- VFMSUBADD231PS
- VFMSUBADD312PD
- VFMSUBADD312PS
- VFMSUBADD321PD
- VFMSUBADD321PS
- VFNMADD123PD
- VFNMADD123PS
- VFNMADD123SD
- VFNMADD123SS
- VFNMADD132PD
- VFNMADD132PS
- VFNMADD132SD
- VFNMADD132SS
- VFNMADD213PD
- VFNMADD213PS
- VFNMADD213SD
- VFNMADD213SS
- VFNMADD231PD
- VFNMADD231PS
- VFNMADD231SD
- VFNMADD231SS
- VFNMADD312PD
- VFNMADD312PS
- VFNMADD312SD
- VFNMADD312SS
- VFNMADD321PD
- VFNMADD321PS
- VFNMADD321SD
- VFNMADD321SS
- VFNMSUB123PD
- VFNMSUB123PS
- VFNMSUB123SD
- VFNMSUB123SS
- VFNMSUB132PD
- VFNMSUB132PS
- VFNMSUB132SD
- VFNMSUB132SS
- VFNMSUB213PD
- VFNMSUB213PS
- VFNMSUB213SD
- VFNMSUB213SS
- VFNMSUB231PD
- VFNMSUB231PS
- VFNMSUB231SD
- VFNMSUB231SS
- VFNMSUB312PD
- VFNMSUB312PS
- VFNMSUB312SD
- VFNMSUB312SS
- VFNMSUB321PD
- VFNMSUB321PS
- VFNMSUB321SD
- VFNMSUB321SS
MOVBE — Move Big-Endian instruction
TSX — Transactional Synchronization Extensions
- XABORT
- XBEGIN
- XEND
- XTEST
Clock domains[edit]
Overclockingedit
- See also: Intel’s XMP
Warning: Overclocking can result in better performance for many types of workloads but it does so by pushing the system beyond its rated specifications. This can reduce the life of the chip, affect system data integrity, reduce system stability, and cause system components to fail.
Overclocking needs to be done on an unlocked part such as the Core i7-5820K, Core i7-5930K, or Core i7-5960X Extreme Edition. Additionally those chips need to be paired with the Intel X99 Chipset.
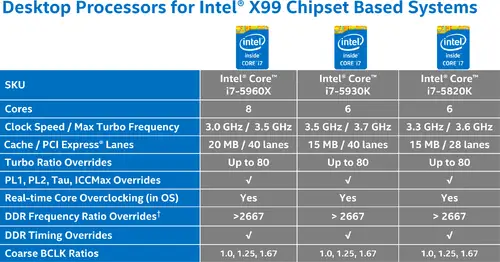
The 5930K and the 5820K are hexa-core parts whereas the 5960X is an octa-core part. Between 28 and 40 PCIe lanes are possible with a core ratio of up to x80 the BCLK.
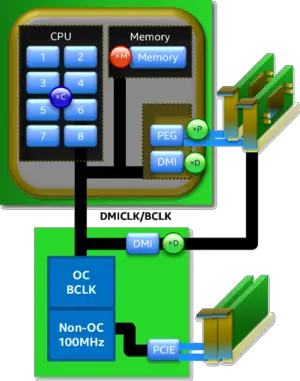
Haswell provides a Coarsed BCLK ratios of either 100 MHz, 125 MHz, or 167 MHz (this was consequently changed in ). The clock is generated internally by the chipset, but motherboard ODMs could generate it independently. A single BCLK from the PCH is fed in < 1 MHz steps, however in practice the input is very much limited by PCI Express and DMI PLL interface. This works out to 100 MHz ± 5-7% PEG/DMI @ 5:5, 125 MHz ±5-7% PEG/DMI @ 5:4, and 166.66 MHz ±5-7% @ 5:3.
- fCORE = BCLK ×
- fRING = BCLK ×
- FDDR = BCLK × [1.33/1.00] ×
All the clock domains in Haswell are derived from the BCLK (also called DMICLK). In the diagram on the right (xC) refers to the Core Frequency and is represented as a multiple of BCLK (Core Frequency = BCLK × Core Freq Multiplier up to x80). Likewise (xM) refers to the memory ratio (up to 2667 MT/s in granularity operations of 200 and 266 MHz) and Two additional multipliers to adjust the PEG(PCIe & Graphics)/DMI links which should remain at a nominal frequency of 100 MHz.
Voltage control is done by Haswell’s new FIVER (Full Integrated Voltage Regulator) based architecture. This means that voltage arrives via the VCCin input from the motherboard into the processor and onto the voltage regulator (VCCin = SVID 1.8 V Nom up to 2.3 V+). Internally, the various voltage planes are all derived from there. This includes the VCORE, VRING, and VSA. With the memory voltage (VDDQ = 1.2 V Nom) provided from the motherboard with to its own rail.
Особенности Haswell
Haswell – название новой архитектуры процессоров, процессоры, основанные на ней, называются также. Вычислительное ядро устройства претерпело изменения по сравнению с предыдущей версией. Предпроцессор почти не изменен. Декодер ядра четырехканальный, а так как средняя длина команды составляет 4 байта, может одновременно обрабатывать до 16 – ти байт. Состоит из четырех простых декодеров и одного сложного. Инструкции декодируются по технологиям Macro – Fusion и Micro – Fusion.
8-миканальный кэш декодированных операций хранит 1500 микроопераций в 4 байта. Каждый из 8-ми банков по 32 кэшстроки, в которые входит по 6 микроопераций в каждую. Смысл такого банка в том, чтобы не выполнять повторное декодирование, а вытаскивать уже декодированную операцию непосредственно из кэша.
Изменены исполнительные блоки в ядре. Количество портов увеличено до 8. Теперь за один такт выполняется до 8-ми микроопераций. Введен новый набор инструкций.
Тесты устройства на производительность проводились на основе Windows и Андроид. Тестирование intel core i7 – 4770 проводилось базовыми процессами и приложениями, а за показатель бралось время выполнения заданной операции. В результате теста на неигровых приложениях индексы процессоров intel Haswell оказались выше, чем в предыдущих моделях.
Наибольший прирост по показателю в приложениях Photoshop, Adobe Premier Pro и др
Преимущества процессора Haswell
Haswell – поколение Intel Core, имеющее довольно много противников. Они находят в нем недостатки, такие как завышенная цена или необходимость слишком часто обновлять платформу. Однако у данного оборудования есть ряд плюсов. Это и высокие эффективность и производительность, и функциональная платформа и др.
- Главный же плюс, которым обладает процессор – интегрированное ядро графики. Оно стало конкурентоспособным. Появилась возможность поддержки нескольких мониторов и значительный прирост производительности;
- Устройство обладает повышенной эффективностью по энергопотреблению. По сравнению с прошлыми версиями удалось снизить его на 5 Ватт в режиме бездействия. Это не столь большая разница для настольного ПК, но значительная, если Вы выбираете ноутбук или ультрабук. Потребление электроэнергии под нагрузкой низкое;
- Производительность повысилась на 5 – 10 % в сравнении с прошлыми поколениями. Отличается в зависимости от условий теста. В отдельных случаях может быть выше или ниже. Разница не столь значительная, чтобы проводить апгрейд существующей системы предыдущего поколения, однако значительная, если Вы выбираете процессор haswell взамен значительно устаревшего;
- Система разгона процессора через базовую частоту стала более гибкой. Тем самым разработчики ответили на претензии пользователей предыдущих версий устройств.
ПОСМОТРЕТЬ ВИДЕО
Страница 1: Intel представила процессоры «Haswell Refresh» и платформу Z97 (тесты)
В последние дни ряд производителей материнских плат представили новые модели на чипсете Z97, а Intel ещё в середине апреля добавила в официальный прайс-лист новые процессоры «Haswell Refresh», так что объявление новых CPU было делом времени. И сегодня, в воскресенье, новые процессоры «Haswell Refresh» уже объявлены. Впрочем, серьёзного обновления ожидать не стоит, 27 новых CPU получили прирост тактовой частоты, изменений архитектуры и техпроцесса не предусмотрено.
В зависимости от модели процессора можно ожидать прирост 100 МГц базовой частоты и частоты Turbo, что несколько оправдывает обновление. Флагманом «Haswell Refresh» является Intel Core i7-4790, который работает с базовой частотой 3,6 ГГц, четыре вычислительных ядра CPU поддерживают выполнение двух потоков одновременно (на ядро CPU) благодаря Hyper-Threading, максимальная частота составляет до 4,0 ГГц, в зависимости от нагрузки. Кроме того, процессор оснащён 8 Мбайт кэша L3, в него встроено графическое ядро HD Graphics 4600. Самый быстрый процессор Intel «Haswell», а именно Core i7-4770K, работал на частоте 3,5 ГГц (до 3,9 ГГц), архитектурные спецификации были схожие.
У некоторых моделей CPU в обновлении «Haswell Refresh» появились версии «S» и «T», которые работают со сниженным напряжением и обеспечивают более высокую эффективность. Например, кроме Intel Core i7-4790 были представлены процессоры Core i7-4790T и i7-4790S, которые работают с базовой частотой 3,2 ГГц и 2,7 ГГц, цена составляет 303 доллара — в партиях по 1000 штук.
Следующие по рейтингу процессоры в линейке Core i5 лишены поддержки Hyper-Threading. Также и кэш у них меньше — 6 Мбайт. Самым младшим процессором здесь является Intel Core i5-4460 3,2 ГГц с ценой 182 доллара США.
Семейство Core i3 урезано по объёму кэша L3 и числу ядер. Как правило, вам придётся довольствоваться двумя ядрами, объём кэша L3 составляет 3 или 4 Мбайт. Процессоры Pentium и Celeron находятся в нижней части списка «Haswell Refresh», они оснащаются двумя ядрами CPU, кэшем L3 2 или 3 Мбайт, поддержка Hyper-Threading тоже отсутствует.
| Модель | Ядра/Потоки | Частота | Кэш L3 | Цена |
|---|---|---|---|---|
| Celeron G1840 | 2 / 2 | 2,8 ГГц | 2 Мбайт | $42 |
| Celeron G1840T | 2 / 2 | 2,5 ГГц | 2 Мбайт | $42 |
| Celeron G1850 | 2 / 2 | 2,9 ГГц | 2 Мбайт | $52 |
| Pentium G3240 | 2 / 2 | 3,1 ГГц | 3 Мбайт | $64 |
| Pentium G3240T | 2 / 2 | 2,7 ГГц | 3 Мбайт | $64 |
| Pentium G3440 | 2 / 2 | 3,3 ГГц | 3 Мбайт | $75 |
| Pentium G3440T | 2 / 2 | 2,8 ГГц | 3 Мбайт | $75 |
| Pentium G3450 | 2 / 2 | 3,4 ГГц | 3 Мбайт | $86 |
| Core i3-4150 | 2 / 4 | 3,5 ГГц | 3 Мбайт | $117 |
| Core i3-4150T | 2 / 4 | 3,0 ГГц | 3 Мбайт | §117 |
| Core i3-4350 | 2 / 4 | 3,6 ГГц | 4 Мбайт | $138 |
| Core i3-4350T | 2 / 4 | 3,1 ГГц | 4 Мбайт | $138 |
| Core i3-4360 | 2 / 4 | 3,7 ГГц | 4 Мбайт | $149 |
| Core i5-4460 | 4 / 4 | 3,2 ГГц | 6 Мбайт | $182 |
| Core i5-4460S | 4 / 4 | 2,9 ГГц | 6 Мбайт | $182 |
| Core i5-4460T | 4 / 4 | 1,9 ГГц | 6 Мбайт | $182 |
| Core i5-4570S | 4 / 4 | 2,9 ГГц | 6 Мбайт | $192 |
| Core i5-4590 | 4 / 4 | 3,3 ГГц | 6 Мбайт | $192 |
| Core i5-4590S | 4 / 4 | 3,0 ГГц | 6 Мбайт | $192 |
| Core i5-4590T | 4 / 4 | 2,0 ГГц | 6 Мбайт | $192 |
| Core i5-4690 | 4 / 4 | 3,5 ГГц | 6 Мбайт | $213 |
| Core i5-4690S | 4 / 4 | 3,2 ГГц | 6 Мбайт | $213 |
| Core i5-4690T | 4 / 4 | 2,5 ГГц | 6 Мбайт | $213 |
| Core i7-4785T | 4 / 8 | 2,2 ГГц | 8 Мбайт | $303 |
| Core i7-4790 | 4 / 8 | 3,6 ГГц | 8 Мбайт | $303 |
| Core i7-4790S | 4 / 8 | 3,2 ГГц | 8 Мбайт | $303 |
| Core i7-4790T | 4 / 8 | 2,7 ГГц | 8 Мбайт | $303 |

По сравнению с предыдущими моделями Intel не вносила серьёзных изменений. В данном случае следует дождаться процессоров «K», в которых Intel добавит ряд улучшений. Как нам кажется, они будут лучше разгоняться из-за улучшенных материалов по сравнению с предыдущими процессорами «Haswell». Скорее всего, Intel улучшила материал TIM (Thermal Interface Material) между распределителем тепла и кристаллом, который значительно улучшает охлаждение. Конечно, открытый множитель тоже имеется. На рынок процессоры «K», подобные Intel Core i7-4790K, должны выйти во второй половине года. Скорее всего, они появятся в момент старта выставки Computex 2014, которая откроется в начале июня.
Но пока что придётся довольствоваться ускорением «Haswell». Новые процессоры «Haswell Refresh» устанавливаются в нынешний Socket LGA1150, но их можно использовать и с материнскими платами Z97, которые и являются самой серьёзной инновацией «Haswell Refresh»: подробности о чипсете Z97 или H97 вы можете прочитать на следующей странице.
<>Intel представила процессоры «Haswell Refresh» и платформу Z97 (тесты)Обзор нового чипсета Z97
Core[edit]
Front-endedit
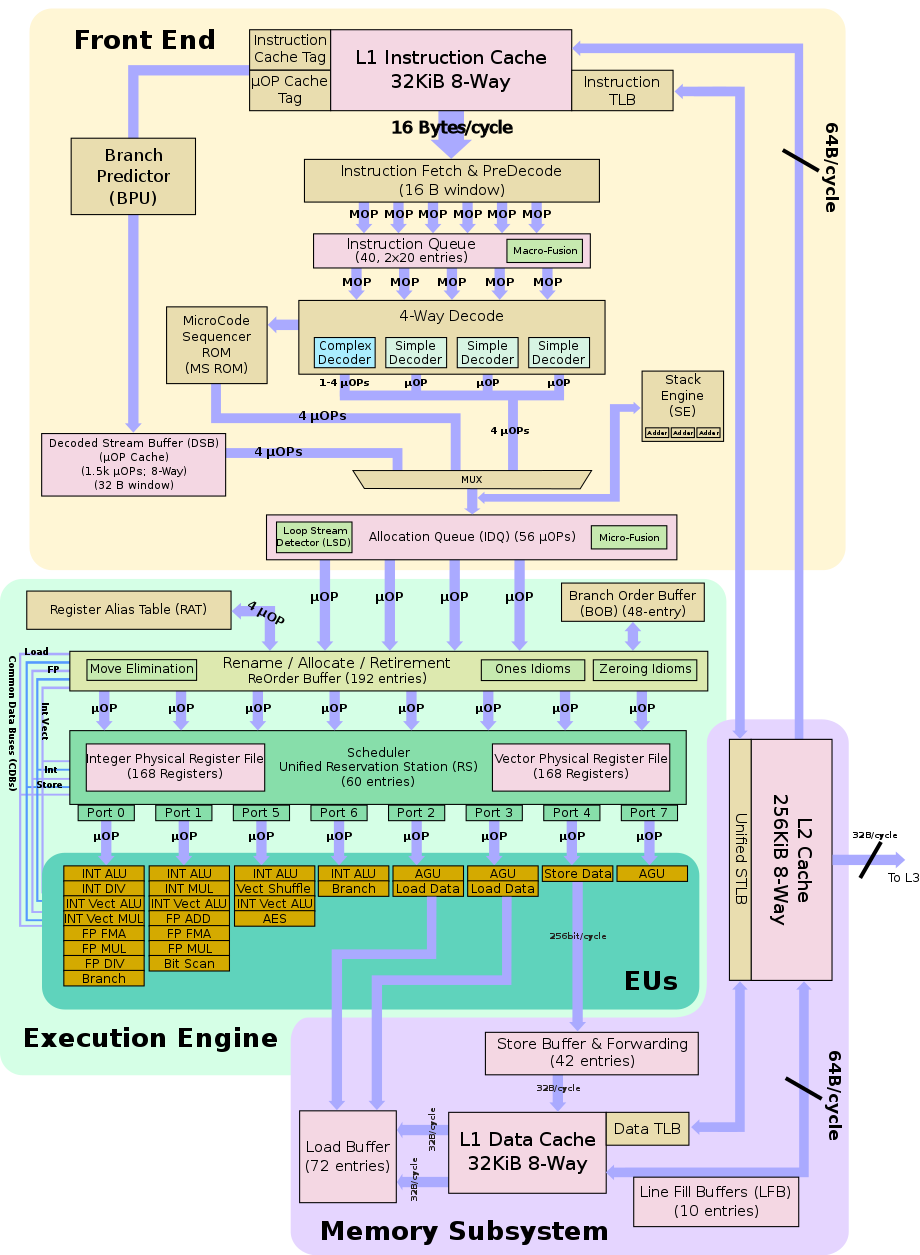
The front-end is the complicated part of the microarchitecture as it deals with variable length x86 instructions ranging from 1 to 15 bytes. The main goal here is to fetch and decode correctly the next set of instructions. The caches have not changed in Haswell from Ivy Bridge, with the L1i$ still 32KB , 8-way set associative shared dynamically by the two threads. Instruction cache instruction fetching remains 16B/cycle. TLB is also still 128-entries, 4-way for 4KB pages and 8-entries, fully associative for 2MB page mode. The fetched instructions are then moved on to an instruction queue which has 40 entries, 20 for each thread. Haswell continued to improve the branch misses although the exact details have not been made public.
Haswell has the same µOps cache as Ivy Bridge — 1,536 entries organized in 32 sets of 8 cache lines with 6 µOps each. Hits can yield up to 4-µOps/cycle. The cache supports microcoded instructions (being pointers to ROM entries). Cache is shared by the two threads.
Following the instruction queue, instructions are coded via the complex 4-way decoder. The decoder has 3 simple decoders and 1 complex decoder. In total, they are capable of emitting 3 single fused µOps and an additional 1-4 fused µOps. The unit handles both micro and macro fusions. Macro-fusion as a result of compatible adjacent µOps may be merged into a single µOp. Push and pops as well as call and return are also handled at this stage. 4 instructions, but with the aid of the macro-fusion, up to 5 instructions can be decoded each cycle.
Execution engineedit
Continuing with the decoder is the register renaming stage. This is crucial for out-of-order execution. In this stage the architectural x86 registers get mapped into one of the many physical registers. The integer physical register file (PRF) has been enlarged by 8 addition registers for a total 168. Likewise the FP PRF was extended by 24 registers bringing it too to 168 registers. The larger increase in the FP PRF is likely to accommodate the new AVX2 extension. The ROB in Haswell has been increased to 192 entries (from 168 in Ivy) where each entry corresponds to a single µOp. The ROB is fixed split between the two threads. Additional scheduler resources get allocated as well — this includes stores, loads, and branch buffer entries. Note that due to how dependencies are handled, there may be more or less µOps than what was fed in. For the most part, the renamer is unified and deals with both integers and vectors. Resources, however, are partitioned between the two threads. Finally, as a last step, the µOps are matched with a port depending on their intended execution purpose. Up to 4 fused µOps may be renamed and handled per thread per cycle. Both the load and store in-flight units were increased to 72 and 42 entries respectively.
Haswell continues to use a unified scheduler for all µOps which holds 60 entries. µOps at this stage sit idle until they are cleared to be executed via their assigned dispatch port. µOps may be held due to resource unavailability.
Following a successful execution, µOps retire at a rate of up to 4 fused µOps/cycle. Retirement is once again in-order and frees up any reserved resource (ROB entries, PRFs entries, and various other buffers).
Execution Unitsedit
Some of the biggest architectural changes were done in the area of the execution units. Haswell widened the scheduler by two ports — one new integer dispatch port and a new memory port bringing the total to 8 µOps/cycle. The various ports have also been rebalanced. The new port 6 adds another Integer ALU designs to improve integer workloads freeing up Port 0 and 1 for vector works. It also adds a second branch unit to lower the congestion for Port 0. The second port that was added, Port 7 adds a new AGU. This is largely due to the improvements for AVX2 that roughly doubled its throughput. Port 0 had its ALU/Mul/shifter extended to 256-bits; same is true for the vector ALU on port 1 and the ALU/shuffle on port 5. Additionally a 256-bit FMA unit were added to both port 0 and port 1. The change makes it possible for FMAs and FMULs to issue on both ports. In theory, Haswell can peak at over double the performance of Sandy Bridge, with 16 double / 32 single precision FLOP/cycle + Integer ALU option + Vector operation.
The scheduler dispatches up to 8 ready µOps/cycle in FIFO order through the dispatch ports. µOps involving computational operations are sent to ports 0, 1, 5, and 6 to the appropriate unit. Likewise ports 2, 3, 4 and 7 are used for load/store and address calculations.
Примечания[]
- Энергосберегающие процессоры станут основой будущих инновационных мобильных вычислительных устройств // intel.com
- Intel B85 Chipset // intel.com
- Haswell review: Intel’s Core i7-4770K takes over the pole position // Extremetech. By Joel Hruska on June 1, 2013: «Today, Intel is launching its much-discussed line of Haswell processors. By the end of the day, you should be able to pick up a Core i7-4770K for $339 from your favorite component stockist. »
- Intel’s Newest Core Processors: All About Graphics And Low Power // 6/04/2013 «Intel today launched today at Computex a dizzying array of new processors «
- Haswell New Instruction Descriptions Now Available!
- ↑ More details on the future AVX instruction set 2.0
- Bit manipulations using BMI2
- Transactional Synchronization in Haswell
- Будущие процессоры Intel смогут поддерживать транзакционную память, cybersecurity.ru 09.02.2012
- Шаблон:Cite web
- Ноутбуки на базе Intel Haswell смогут проработать сутки без подзарядки, ferra.ru 14.09.2011
- Шаблон:Cite web
- Шаблон:Cite web
- Шаблон:Cite web
- ↑ Определён ассортимент процессоров Intel Haswell-E
- Особенности разгона процессоров Intel Haswell
- Intel 2012 Haswell CPUs Will Feature Improved Multi-Core Support
- Шаблон:Cite web
- Шаблон:Cite web
Эпоха многоядерных процессоров в истории Intel
Первые Intel Core были основаны на архитектуре P6, но с двухъядерной конфигурацией. Однако они разработали второе поколение, которое было революционным и считается лучшим процессором 2000-х годов.
Для своего развития Intel скопировала несколько идей в Opteron от AMD; как и реализация северного моста в процессоре и принятие 86-разрядного расширения x64. Что касается производительности, они почти вдвое увеличили IPC, и это третий по величине скачок производительности после того, как был достигнут с 80286 и 80486. Для этого они улучшили выполнение вне очереди, сделали ЦП способным обрабатывать больше инструкций в параллельно, и они сначала добавили Smart Cache в процессоры Intel.
Однако Core 2 можно было считать нулевым поколением, поскольку Intel начала использовать марки Intel Core i3, i5 и i7 из архитектуры Nehalem, считающейся Intel Core первого поколения. С тех пор до сих пор у нас было несколько поколений с постепенными улучшениями.
- Сэнди / Айви-Бридж: Intel снова улучшила блок предсказания перехода, помимо этого улучшила такие элементы, как кэш микроопераций, блоки целых чисел и с плавающей запятой, а также производительность некоторых инструкций для выборки данных из памяти.
- Haswell / Broadwell: Intel снова увеличила количество инструкций, которые ЦП может выполнять за цикл, помимо увеличения пропускной способности внутренних кешей процессора и улучшения контроллера памяти. Они также включали внутрипроцессорный контроллер напряжения (FIVR).
- Поколение SkyLake: Intel увеличила количество инструкций, которые процессор может декодировать, но не увеличила количество инструкций, которые он может выполнять параллельно. Изменения по сравнению с предыдущими поколениями очень небольшие (убрали FIVR).
- Ракетное озеро-С / Тигровое озеро: Это текущие Rocket Lake-S и Tiger Lake. После нескольких лет небольших улучшений в IPC Intel решила пойти по пути AMD, чтобы не отставать.
Его последний выпуск — Intel Core 12 с архитектурой Alder Lake-S, который добавляет больше новинок с момента запуска Intel Core 2, таких как исполнение с гетерогенными ядрами, добавление Thread Director и других новинок, которые мы не делаем. знайте, будет ли это большим скачком между поколениями, который компания совершает каждое десятилетие, или же под капотом будет что-то еще, ясно то, что история Intel по крайней мере захватывающая.
Особенности архитектуры[]
- Конструктивное исполнение LGA 1150 (Socket H3)
- Базовое количество ядер — 2 или 4
- Полностью новый дизайн кэша
- Улучшенные механизмы энергосбережения
- Поддержка технологии Thunderbolt
- Интегрированный векторный сопроцессор
- Добавление инструкций AVX 2; FMA (Fused Multiply Add); битовых инструкций BMI1 и BMI2
- Расширение команд TSX (Шаблон:Нп3) для аппаратной поддержки транзакционной памяти (кроме процессоров с индексом K). В начале августа 2014 один из разработчиков обнаружил неправильную работу инструкций TSX, что Intel впоследствии подтвердила собственными тестами и выпустила новый микрокод, который полностью отключает новый набор команд. К „дефектным“ процессорам относятся все модели Haswell и Haswell-E.
- Память eDRAM объёмом 64 Мбайт (по некоторым сведениям — 128 МБ) как отдельный кристалл, но в общей упаковке — только в процессорах для BGA, например Core i7-4770R
- Энергопотребление на 30 % ниже по сравнению с аналогами из линейки Sandy Bridge; в некоторых режимах — в 20 раз ниже.
В чипе реализована возможность одновременной работы с четырьмя операндами, позволяющая за одну инструкцию совершать сразу две операции умножения и сложения либо вычитания.
Процессоры, построенные на архитектуре Haswell имеют дополнительный интегрированный регулятор напряжений (VRM, FIVR), выполненный в виде отдельного кристалла под общей теплораспределительной крышкой. FIVR имеет размеры около 13×8 мм и изготовлен по 90 нм процессу.
Убийство RISC, эпоха P6
Говорят, что в каждое десятилетие истории Intel вносит большие изменения в свои процессоры, в 80-х именно 80386 обновил ISA до 32 бит, а в 90-х это был Pentium Pro, процессор, который считался лидером. от x86 до рынка рабочих станций, где в то время доминировали архитектуры RISC.
От Intel очень хорошо знали, что набор инструкций x86 имеет ограничения, поэтому Intel создала для этого процессора как неупорядоченное, так и спекулятивное исполнение. Кроме того, было увеличено количество этапов с 5 до 14 и впервые добавлен кэш второго уровня.
Под архитектурой Pentium Pro или P6 вошли различные процессоры, выпущенные как поколения различных коммерческих продуктов.
- Pentium Pro был первым процессором, в котором кэш-память второго уровня была встроена в процессор, до тех пор он был установлен на плате рядом с процессором.
- Что касается Pentium II, он был основан на Pentium Pro, но он переместил кэш L2, хотя и оставил его в том же корпусе, в отличие от своего предшественника, он был запущен для рынка домашних ПК, принося мощность работы станции.
- Pentium III, с другой стороны, включал инструкции SSE и в конечном итоге в конечном итоге интегрировал кэш L2 обратно в процессор.
Стратегия Intel сработала, и в конце 90-х большинство архитектур RISC томились в ожидании своей окончательной смерти. Только ARM и PowerPC, использовавшиеся в Macintosh, выжили, остальные были вооружены дамокловым мечом и вскоре уступили.
Pentium 4, конец эпохи
Для Pentium 4 Intel создала новую архитектуру под названием Netburst, которая следовала модной тенденции дня и добавляла большое количество ступеней для достижения высокой тактовой частоты. Именно с этим процессором Intel достигла потолка скорости, и было обнаружено, что гонка, основанная на этой метрике, не имеет будущего из-за высокого потребления процессоров и температуры, которую они генерируют.
Благодаря опыту с Pentium 4 показатель «мощность на ватт» стал иметь значение и начал разрабатывать процессоры, уже основанные на концепции многоядерности. В частности, причина заключалась в том, что их было невозможно установить на ноутбуках, и пришлось продлить срок службы P6, чтобы иметь возможность запускать процессоры для того типа компьютеров, которые создавались в то время.
Сплетни говорят, что именно Apple, одержимая своими промышленными разработками, дала Intel понять, сможет ли она создать ядро с достаточной производительностью на ватт и большей мощностью, чем PowerPC, только тогда она совершит прыжок на x86. Так оно и было, но вместе с этим они отказались от названия Pentium и приняли другое.
Architecture[edit]
While sharing a lot of similarities with its predecessor Ivy Bridge, Haswell introduces many new enhancements and features. Haswell is the first desktop-line of x86s by Intel tailored for a system on chip architecture. This is a significant move that will continue to be developed over the next couple of microarchitectures. Overall Haswell shares the same basic flow as Sandy Bridge and Ivy but expands on them considerably in the execution engine with wider execution units and additional scheduler ports.
Key changes from Ivy Bridgeedit
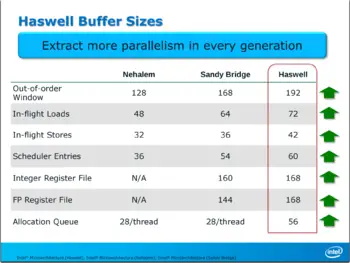
- 3.5x performance/watt over Nehalem
- Platform Controller Hub (PCH)
- Support for DDR4 (server/enthusiast segments)
- Full Integrated voltage regulator (FIVR)
- New C6 & C7 sleep states
- Cache
- L1D$ has double the bandwidth
- Load: 64B/cycle (up from 32B/cycle)
- Store: 32B/cycle (up from 16B/cycle)
- L2$ bandwidth to L1 is doubled
- STLB been made to support 2MB pages
- L1D$ has double the bandwidth
- Reorder Buffer (ROB) was increased to 192 entries (up from 168)
- Scheduler has been widened, (see )
- Increased to 60 entries (up from 54)
- Integer register file up 8 entries to 168
- FP register file up 24 entries to 168
- 2 additional execution ports (see )
- New memory model for Transactional Synchronization Extensions
CPU changesedit
Haswell can do many general purpose instructions with 4 ops/cycle throughput. SandyBridge/Ivybridge could do so only for NOPs, CLC, some vector MOVs and some zeroing instructions (SUB, XOR and vector analogs).
- MOVSX and MOVZX have 4 op/cycle throughput for 8->32, 8->64 and 16->64 bit forms.
- Many ALU operations have 4 op/cycle throughput for GP registers: XOR, OR, NEG, NOT, ADD, SUB, CMP, AND, etc.
- Variable shifts and rotates (SHL r32, CL etc) latency increased from 1 cycle to 2 cycles, variable SHLD/SHRD from 2 cycles to 4 cycles.
- REP MOVS copy is twice as fast: now ~52 bytes/cycle.
- REP STOS fill is twice as fast: now ~30 bytes/cycle.
GPU changesedit
- Direct3D 11.1
- OpenGL 4.3
- OpenCL 1.2
- Four versions of GPU options codenamed GT1, GT2, GT3 and GT3 (with GT3e having a dedicated eDRAM L4$)
New instructionsedit
Haswell introduced a number of new instructions:
- — Advanced Vector Extensions 2; an extension that extends most integer instructions to 256 bits vectors.
- — Bit Manipulation Instructions Sets 1
- — Bit Manipulation Instructions Sets 2
- — Move Big-Endian instruction
- — Floating Point Multiply Accumulate, 3 operands
- — Transactional Synchronization Extensions
- — Invalidate Process-Context Identifier
- — Leading zero count
Individual Coreedit
Memory Hierarchyedit
The memory hierarchy in Haswell had a number of changes from its predecessor. The cache bandwidth for both load and store have been doubled (64B/cycle for load and 32B/cycle for store; up from 32/16 respectively). Significant enhancements have been done to support the new gather instructions and transactional memory. With Haswell new port 7 which adds an address generation for stores, up to two loads and one store are possible each cycle.
- Cache
- L1I Cache:
- 32 KB 8-way set associative
- 64 B line size
- Write-back policy
- shared by the two threads, per core
- 32 KB 8-way set associative
- L1D Cache:
- 32 KB 8-way set associative
- 64 B line size
- shared by the two threads, per core
- 4 cycles for fastest load-to-use
- 64 Bytes/cycle load bandwidth
- 32 Bytes/cycle store bandwidth
- Write-back policy
- 32 KB 8-way set associative
- L2 Cache:
- unified, 256 KB 8-way set associative
- 11 cycles for fastest load-to-use
- 64B/cycle bandwidth to L1$
- Write-back policy
- L3 Cache:
- 1.5 — 3 MB
- Write-back policy
- Per core
- L4 Cache:
- 128 MB
- Per package
- Only on the Iris Pro GPUs
- L1I Cache:
Haswell TLB consists of dedicated level one TLB for instruction cache and another one for data cache. Additionally there is a unified second level TLB.
- TLBs:
- ITLB
- 4KB page translations:
- 128 entries; 4-way set associative
- dynamic partition; divided between the two threads
- 2MB/4MB page translations:
- 8 entries; fully associative
- Duplicated for each thread
- 4KB page translations:
- DTLB
- 4KB page translations:
- 64 entries; 4-way set associative
- fixed partition; divided between the two threads
- 2MB/4MB page translations:
- 1G page translations:
- 4KB page translations:
- STLB
- 4KB+2M page translations:
- 1024 entries; 8-way set associative
- shared
- 4KB+2M page translations:
- ITLB
Обзор Haswell
С 2013 – го года разработано множество моделей процессоров. Автономный процессор позиционировался разработчиками для использования в ноутбуках, ультрабуках и планшетах, благодаря низкому энергопотреблению. Производительность повысится, что позволяет разработчикам представлять Haswell как лучшие процессоры intel для мобильных устройств в настоящий момент. Двухядерные процессоры Core i3 haswell представлены в трех разновидностях:
- i3-4340;
- i3-4330;
- i3-4130.
Различаются тактовой частотой, которая для трех моделей составляет соответственно 3,6, 3,5, 3,4 ГГц. Новое графическое ядро для первых двух моделей представлено HD Graphics 4600, а для третьей — HD Graphics 4400. Частота это ядра у всех 1150 МГц. LЗ – кэш 4, 4 и 3 Мбайта соответственно. Цена отличается несильно – для первого варианта – $160, для второго – $150 и для третьего $130.
Четырехядерные i5 haswell оснащены ядром графики HD Graphics 4600. Тактовая частота 3,2 ГГц, при турбоускорении – 3,6. Кэш объемом 6 Мбайт. Теплоотделение низкое, так что и при активном использовании не требуется дополнительный куллер.
Но процессор i7 превосходит i3 или i5. Представлен рядом i7-4770K, i7-4770, i7-4770S, i7-4770T и i7-4765T. Первые два работают на четырехядерном процессоре в 8 потоков, тогда как остальные – в четыре.
Тактовая частота ниже всего у последней модели и равна 2 ГГц, самая высокая у первой – 3,5 ГГц. Кэш 8 Мб
» Haswell-WS » (22 морских миль)
Xeon E3-12xx v3 (однопроцессор)
| Модель номер | sSpec номер | Ядра | Частота | Турбо |
Модель графического процессора |
Частота GPU |
TDP | Разъем | Шина ввода / вывода | Дата выхода | Часть номер (а) |
Отпускная цена (долл. США) |
||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Двухъядерный, сверхнизкое энергопотребление | ||||||||||||||
| 2 | 1,1 ГГц | 2/4 | 2 × 256 КБ | 4 МБ | N / A | N / A |
13 Вт |
LGA 1150 | DMI 2.0 | Сентябрь 2013 | 193 долл. США | |||
| Четырехъядерный | ||||||||||||||
| 4 | 3,1 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
193 долл. США 203 долл. США | ||
|
4 | 3,2 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1200 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
213 долл. США 224 долл. США | |
| 4 | 3,3 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1200 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. |
|
213 долл. США | ||
| 4 | 3,3 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
240 долларов США 250 долларов США | ||
| 4 | 3,4 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. |
|
240 долл. США | ||
| 4 | 3,4 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
262 долл. США 273 долл. США | ||
| 4 | 3,5 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. |
|
262 долл. США | ||
| 4 | 3,4 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1200 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
276 долларов США 287 долларов США | ||
| 4 | 3,5 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1200 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. |
|
276 долл. США | ||
| 4 | 3,5 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
328 долларов 339 долларов | ||
| 4 | 3,6 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
80 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. |
|
328 долларов США | ||
| 4 | 3,5 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1250 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 |
|
339 $ 350 $ | ||
| 4 | 3,6 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1250 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. |
|
339 долл. США | ||
| 4 | 3,6 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
82 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 | 612 долл. США | |||
|
4 | 3,7 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | N / A | N / A |
82 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. | 612 долл. США | ||
| 4 | 3,6 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4700 | 350–1300 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 | 662 долл. США | |||
| 4 | 3,7 ГГц | 2/3/4/4 | 4 × 256 КБ | 8 МБ | HD Графика P4700 | 350–1300 МГц |
84 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. | 662 долл. США | |||
| Четырехъядерный процессор, низкое энергопотребление | ||||||||||||||
| 4 | 2,5 ГГц | 09.06.11.12 | 4 × 256 КБ | 8 МБ | HD-графика (10 EU) | 350–1200 МГц |
45 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 | 294 долл. США | |||
| 4 | 2.3 ГГц | 07.06.09.10 | 4 × 256 КБ | 8 МБ | HD Графика P4600 | 350–1000 МГц |
45 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 | 377 долл. США | |||
|
4 | 2,7 ГГц | 09.06.11.12 | 4 × 256 КБ | 8 МБ | HD-графика (10 EU) | 350–1200 МГц |
45 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. | 328 долларов США | ||
| 4 | 1,8 ГГц | ? /? /? / 14 | 4 × 256 КБ | 6 МБ | Ирис Pro Графика 5200 | 750–1000 МГц |
47 Вт |
BGA-1364 | DMI 2.0 | Февраль 2014 года | OEM | |||
|
4 | 3,1 ГГц | 05.04.08 | 4 × 256 КБ | 8 МБ | HD Графика P4700 | 350–1250 МГц |
65 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 | 774 долл. США | ||
| 4 | 3,2 ГГц | 05.04.08 | 4 × 256 КБ | 8 МБ | HD Графика P4700 | 350–1250 МГц |
65 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. | 774 долл. США | |||
| Четырехъядерный процессор, сверхнизкое энергопотребление | ||||||||||||||
| 4 | 1,8 ГГц | 07.06.09.10 | 4 × 256 КБ | 8 МБ | N / A | N / A |
25 Вт |
LGA 1150 | DMI 2.0 | июнь 2013 | 250 долл. США | |||
| 4 | 2 ГГц | 07.06.09.10 | 4 × 256 КБ | 8 МБ | N / A | N / A |
25 Вт |
LGA 1150 | DMI 2.0 | Май 2014 г. | 278 долл. США |