Программа для восстановления сайтов из вебархива
Содержание:
Как сохранить страницу с интернета на компьютер
Интернет для большинства людей является своего рода библиотекой, справочником и путеводителем. Он представляет возможность человеку развиваться, увеличивать свой уровень образованности и знаний. С его помощью можно получить ответы на интересующие вопросы, изучать те или иные темы, в том числе даже на иностранных языках, ведь почти все браузеры имеют встроенные переводчики. В общем, это кладовая информации с неограниченным потенциалом. Многие люди уже не представляют повседневную жизнь без интернета.
Бывают случаи, когда пользователь находит интересные для себя статьи и публикации, но не хватает времени прочесть в связи с очень плотным графиком жизни. Он бы занял себя чтением по дороге на работу, или ему необходимо срочно посмотреть какую-то инструкцию, но нет возможности подключится к интернету.
Много людей сталкиваются с такой проблемой, поэтому рассмотрим способы, сохранения страницы из интернета на компьютер. Итак, как сохранить страницу сайта и просматривать её в режиме оффлайн (без подключения к интернету).
Способы сохранения страницы сайта в популярных браузерах
В каждый интернет браузер встроена функция сохранения веб страницы на компьютер. Рассмотрим, на примере, как сохранить страницу сайта в браузере Opera.
Переходим в браузере Opera на страницу, которую вы хотите сохранить. В верхнем левом углу браузера отображается кнопка «Opera», при переходе на которую всплывает меню. В выпадающем меню после нажатия на вкладку «Страница» высветится пункт «Сохранить как…». Есть и более простой способ, нажав комбинацию клавиш Ctrl+S.
После нажатие на этот пункт будет предложено указать место на диске, где вы хотите сохранить файл, и выбрать его тип. По умолчанию страница сайта сохраняется в формате «Веб-архив (единственный файл)» с расширением mht. Этот формат очень удобен, ведь все элементы сайта, в том числе картинки, будут сохранены полностью и находиться в одном файле. Кроме Оперы в таком формате ещё сохраняет браузер Internet Explorer.
При сохранении как «HTML с изображениями», кроме файла с таким расширением, на компьютере создастся отдельный каталог с картинками и прочими элементами. Несмотря на то, что страница будет сохранена полностью, это не столь удобно. Ведь при копировании на флешку, порой для каталога с «увесистыми» картинками может не хватить места, и тогда сохраненный сайт откроется в виде одного текста, что не очень удобно при просмотре.
Если вам картинки не важны, есть возможность полностью сохранить её на компьютер в текстовом формате с расширением txt.
Процесс сохранения в других браузерах аналогичен, но есть некоторые нюансы. Так в браузере Google Chrome, пункт «Сохранить страницу как…» находится в меню настроек и управления (квадрат в верхнем правом углу с тремя линиями). Кроме того, Chrome не поддерживает сохранение в текстовом и архивном файле. В браузерах Mozilla Firefox и Internet Explorer пункт «Сохранить как…» появляется в выпадающем меню при нажатии на кнопку «Файл».
Как сохранить веб страницу в PDF формате
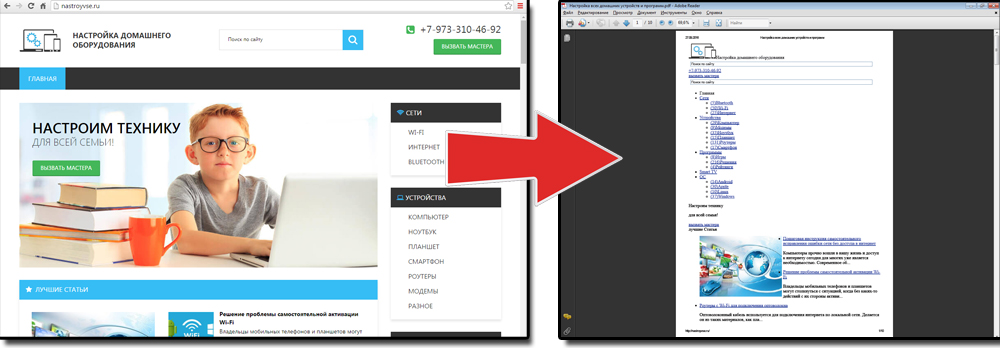
Для многих сохранение страницы на компьютер через веб браузер может показаться не столь удобным, ведь кроме неё подтягивается и каталог с изображениями и массой отдельным элементов. Намного компактнее сохранить страницу в PDF. Такую возможность предоставляет браузер Google Chrome, к тому же, она будет сохранена на компьютере полностью.
Для сохранения в PDF заходим в меню управления и настроек и нажимаем на пункт «Печать». После появляется окно печати документа. В подпункте «Принтер» нажимаем на кнопку «Изменить». Перед нами появляются все доступные принтеры, а также строка «Сохранить как PDF». После нажимаем на «Сохранить» и указываем место на диске, где вы хотите сохранить интернет-страницу.
Сохранение через снимок экрана (скриншот)
Еще вариант, сохранить веб страницу из интернета в виде картинки. Для этого откройте страницу в интернете и сделайте её скриншот с помощью комбинации клавиш Shift+Print Screen. При каком способе вам не удастся сохранить её целиком, а только часть, которая входит в рамки экрана. Если какой-то фрагмент текста немного выходим за рамки, можно постараться уменьшить захват экрана через изменения масштаба. Затем откройте любой графический редактор и вставьте полученную картинку.
Если вам нужна картинка веб страницы целиком, можно сохранить её на компьютере в PDF, а затем конвертировать, например, в JPG формат.
WinRAR
Ключевое назначение программы WinRAR – сжатие файлов и распаковка ранее созданных архивов. Приложение функционирует на большинстве популярных операционных систем: Windows 10/11 (32/64-bit) и ниже, macOS, Linux, совместимо с мобильными платформами Android, iOS.
Архиватор имеет мультиязычный интерфейс. Последняя версия утилиты доступна на русском языке и еще 42 лингвистических интерпретациях.
Функциональные возможности
Программа WinRAR, наряду с собственными алгоритмами сжатия цифровых данных, поддерживает технологии архивации аналогичных утилит. Приложение способно извлекать файлы из пакетов ZIP/ZIPX, ARJ, LZH, ISO, CAB, 7z, TAR, ряда других форматов.

Со времени первого релиза (1995) программа приобрела арсенал важных функций:
- создание самораспаковывающихся exe-модулей;
- внедрение комментариев к архивам, файлам (недоступно в формате RAR5);
- компоновка многотомных пакетов установленного размера;
- структурное архивирование с сохранением директорий и внутренних каталогов;
- формирование solid (непрерывных) пакетов – технология, используемая для максимального сжатия однотипных файлов;
- добавление данных в формате циклического кода для восстановления информации;
- защита архивов паролем.
Последняя версия WinRar 64-bit предоставляет 6 базовых алгоритмов: от режима «просто для хранения» до максимального сжатия.
Альтернативно, варьировать степень компоновки архива можно изменением длины словаря в интервале 1 – 128 MB. Архиватор может работать с графическим интерфейсом или в режиме консоли.
Архиватор WinRAR распространяется условно бесплатно. Стационарная версия программы обеих разрядностей: 64 и 32-бита, для ПК работает без ограничений 40 суток. Мобильное приложение ВинРар 2021 для Андроид устройств – полностью бесплатное.
Преимущества
Весомым усовершенствованием софта выступает поддержка многоядерности современных процессоров, что существенно сокращает время сжатия/распаковки.
Другие достоинства программы связаны с новым форматом архивирования – RAR5, где размер словаря увеличен до 1 ГБ, введен 256-битовый алгоритм хеширования, а также применяется методика симметричного блочного шифрования AES-256.
Установка WinRAR обеспечит быстрое создание резервных копий важной информации, распаковку пакетов, сформированных другими популярными архиваторами. Несмотря на пробный период, все ключевые функции приложения сохраняются после истечения срока бесплатной лицензии
Онлайн скачивание
Что такое url-адрес сайта? Простое объяснение сложных вещей
Этот вариант – отличное решение для тех, кто хочет скачать сайт целиком на компьютер. Уже разработано много разнообразных программ и ресурсов, которые помогут с перекодировкой файлов, с редактированием аудиофайлов.
Одно из самых важных достоинств этого варианта, это то, что нет необходимости захламлять операционную систему лишними утилитами, которыми в лучшем случае вы воспользуетесь только один раз.
Для скачивания достаточно зайти на специальный сайт, вбить адрес нужного вам ресурса, и запустить скачивание, предварительно выбрав папку, где будет храниться сайт.
Теоретически это все просто, а на самом деле найти действительно качественный и безопасный ресурс тяжело, потому что по настоящему их несколько штук.
Конечно, если вы хотите найти бесплатный ресурс.
А остальные хорошие ресурсы, как правило, платные.
Но сейчас хотелось бы рассмотреть именно бесплатные варианты.
Site2Zip com

Site2Zip.com
Бесплатный и, что немаловажно, русскоязычный ресурс. Простой интерфейс поможет быстро разобраться что к чему даже непрофессионалу
В окошко необходимо ввести адрес, капчу и нажать кнопку , все осталось просто подождать
Простой интерфейс поможет быстро разобраться что к чему даже непрофессионалу. В окошко необходимо ввести адрес, капчу и нажать кнопку , все осталось просто подождать.
Действие небыстрое, да и у тех, кто пробует первый раз, может не получиться.
При удачном завершении процесса, то на выходе у нас есть архивированный сайт.
Webparse

Сайт Webparse.ru
С одной стороны вроде бы бесплатный ресурс с одним но. Воспользоваться им бесплатно можно только один раз, дальше за скачивание страниц и сайтов необходимо платить.
Скорость скачивания, безусловно, больше, нежели у вышеописанного ресурса, но уже не бесплатно. На выходе у нас образовывается архив из сайтом.
Глубины парсинга в настройках, к сожалению нет. А это значит убедиться в полной закачке сайта невозможно, необходимо самостоятельно сверять копии и оригинал.
Web2PDFConvert

Сайт Web2PDFConvert.com
Web2PDFConvert.com создает PDF – файл. В этом файле собраны страницы сайта который скачивается.
Соответственно большая часть сайта в процессе потеряется. Если это не будет проблемой, то пользоваться этим ресурсом можно.
4 способа копирования текста с сайта
Ниже будут представлены основные варианты копирования статьи с текста. С помощью этих методик каждый сможет выполнить данный процесс за короткое время.
Самый банальный
Об этом варианте не знают, наверное, только новички, но догадываются и ищут ответ. Рассказываю о стандартном методе копирования.
Алгоритм действий:
- Выделяете текст с помощью нажатия клавиш на клавиатуре: Сначала жмете Ctrl, не отпуская ее жмете на англоязычную буковку «A». Она находится с левой стороны клавы.
- Когда выделение произведено, следующим шагом кликаете на Ctrl опять ее удерживаете и нажимаете на «C». Теперь текст скопирован и его нужно куда-то вставить.
- Выберите место для вставки скопированных слов. Это может быть Word или иной текстовый документ.
- Давите на кнопку Ctrl, снова ее не отпуская нажимаете на «V».
- После этого статья переместится в нужное вам место.
Иногда требуется выполнить копирование не всего содержимого. Особенно так требуется делать на сайтах. Если все выделить, то к вам в документ попадет и реклама и много еще чего лишнего.
Для этого достаточно проделать такой алгоритм:
- Наведите курсор перед нужным текстом и нажмите левую кнопку мыши. Ее нужно удерживать и не отпускать до тех пор, пока не выделите нужный текст.
- Теперь передвигайте мышь в сторону и вниз и буквы будут выделяться.
- Когда дойдете до нужного момента клавишу на мыши можно отпустить.
- Наведите курсор на выделение и нажмите правую кнопку мышки.
- Из предложенных вариантов выберите копировать. Но можно для копирования воспользоваться клавишами Ctrl+C.
Копируем текст с сайта который не копируется
В целях безопасности вебмастера ставят специальные плагины, которые не позволяют получить нужный документ. В действительности эта опция приносит больше неудобств обычному покупателю. Воришка же просто сделает следующее:
- Наведет курсор на текст.
- Нажмет правую кнопку мыши.
- Выберет из предложенных пунктов «Просмотреть код страницы»
- Перейдет на страницу с кодом и текстом.
- Отыщет нужный текст.
- Выделит его с помощью мыши.
- Скопирует с другими элементами.
- Вставит в текстовый редактор, например, Word.
- Выполнит редактирование и уберет не нужный код.
Единственная сложность — это чистка текста от элементов кода.
Копируем текст через Яндекс
Для того чтобы получить текстовый формат этим способом вам потребуется уметь делать скриншоты. Для этого у вас должна стоять программа FastStone Capture или любая другая с аналогичным функционалом.
Алгоритм действий:
- Делаем скриншот нужного текста.
- Заходим на главную страницу поисковика Яндекс и нажимаем картинки.
- Теперь вверху преимущественно по правой стороне нажимаем на значок фото.
- Далее жмем «Выберите файл».
- Выбираете ранее сделанный текст в виде скриншоте. По сути это фотография текста.
- После загрузки с правой стороны появится расшифровка в текстовом формате.
- Копируем нужную информацию путем нажатия Ctrl + С предварительно выделив ее.
Пример показан на скриншоте:

Таким образом Яндекс способен распознать текст, который представлен на фотографии. Возможно в сети есть и другие сервисы по распознанию документов.
Копирование текста с помощью аудио озвучки
Это достаточно интересный способ, но медленный. Используется подобный вариант очень редко, если вообще он применяется.
В общем у вас должно работать 2 сервиса. Всю работу требуется выполнять в Яндекс Браузере.
Алгоритм действий:
- Открываете нужный сайт.
- Запускаете запись звука на онлайн сервисе или на любом другом аналогичном. Главное, чтобы программа аудио переводила в текстовый формат.
- Когда запись идет на открывшемся сайте в Яндекс Браузере запускаем чтение текста с помощью Алисы. Для этого в верху нажимаем на значок наушников. При наведении будет надпись: «Алиса, прочитай эту статью».
- Алиса читает программа слушает и переводит аудио в текст!
- После окончания процедуры выполняете проверку статьи и вносите определенные корректировки.
Минусы этого способа:
- Слишком долго.
- Программа по переводу аудио в текст может глючить.
- Запись идет с внешнего микрофона.
Если у вас получится устранить хотя бы 2 последних минуса, то все же первый может быть реальной проблемой для использования данного способа.
Таким образом сегодня вы узнали целых 4 варианта как копировать текст с сайта!
На этом данная статья подошла к концу, желаю удачи!!!
Поделиться ссылкой:
votes
Рейтинг статьи
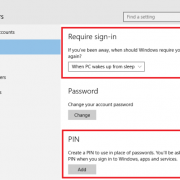
Как добавить копию страницы в web archive
Чтобы не дожидаться, пока бот найдёт и сохранит нужную вам страницу, можете добавить её вручную.
Если используете сайт, перейдите в специальный подраздел. Вставьте ссылку на сохраняемую страницу и нажмите Save Page. Отметьте пункт Save error pages, если хотите, чтобы система архивировала в том числе страницы, которые не открываются из-за ошибок.
Если используете приложение, вставьте ссылку на нужную страницу и нажмите Archive Page Now.
Для быстрого добавления страниц можно также использовать расширения для десктопных браузеров. После установки достаточно открыть в браузере нужную ссылку, нажать на кнопку плагина и выбрать Save Page Now.
Использование сервиса WebArchive
Всем, кто задается вопросом, где посмотреть старые версии сайтов, можно порекомендовать воспользоваться таким интересным сервисом как WebArchive.
Его функционал гораздо шире, чем у кэша поисковиков, можно просмотреть, как видоизменялся сайт за месяцы и годы своего существования, а также воспользоваться поиском по конкретному числу, когда была сохранена копия содержимого страницы.
Для того, чтобы воспользоваться сервисом, в поиске на сайте WebArchive введите адрес искомой страницы. Также поддерживается поиск по ключевым словам, относящимся к тематике ресурса — можно воспользоваться им. Как только вы это сделаете, появится статистика по годам. Черным цветом отмечено, в какое время создавалась резервная копия сайта, сохраненная в архиве.

Как только вы выберете нужный год и перейдете на него, откроется календарь, в котором можно выбрать число, за которое была сохранена резервная копия страницы сайта.
Зеленым и синим цветом отмечены даты, когда поисковые роботы заархивировали страницу и добавили ее к просмотру.
Как правило, возможность просмотра изображений отсутствует, однако текст сохраняется в полном объеме. А если вы ищете какую-либо конкретную статью на определенном ресурсе, есть вероятность, что ссылка на нее могла сохраниться.
Сохранить как PDF
В Google Chrome можно создать из страницы PDF-файл. Данная функция предназначена для распечатки на принтере. Но доступно копирование и на компьютер.
- Кликните на пиктограмму в виде трёх линий (они справа вверху).
- Нажмите «Печать» или воспользуйтесь сочетанием клавиш Ctrl+P.
- Кликните «Изменить».
- Пункт «Сохранить как PDF».
- На левой панели повторно нажмите кнопку с таким же названием.
- Дайте файлу имя и укажите путь.
Еще один способ — сохранить как PDF-страницу с помощью штатных средств Chrome.
Эта функция доступна исключительно в Chrome. Для других веб-обозревателей нужны плагины. Printpdf для Firefox и Web2PDFConvert для Opera.
Скопировать из браузера
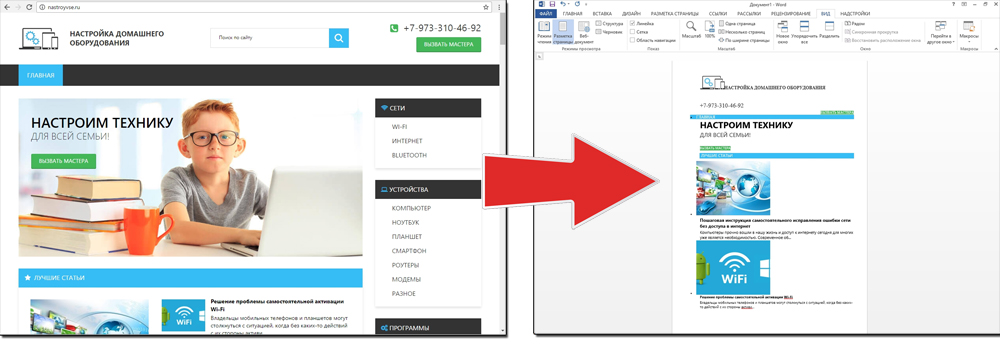
Можно перенести данные из обозревателя в любой текстовый редактор. Для этого лучше всего подойдёт Microsoft Word. В нём корректно отображаются изображения и форматирование. Хотя из-за специфики документа может не очень эстетично выглядеть реклама, меню и некоторые фреймы.
Вот как скопировать страницу сайта:
- Откройте нужный URL.
- Нажмите Ctrl+A. Или кликните правой кнопкой мыши по любой свободной от картинок и flash-анимации области и в контекстном меню выберите «Выделить». Это надо сделать для охвата всей информации, а не какого-то произвольного куска статьи.
- Ctrl+C. Или в том же контекстном меню найдите опцию «Копировать».
- Откройте Word.
- Поставьте курсор в документ и нажмите клавиши Ctrl+V.
- После этого надо сохранить файл.
Иногда получается так, что переносится только текст. Если вам нужен остальной контент, можно взять и его. Вот как скопировать страницу веб-ресурса полностью — со всеми гиперссылками, рисунками:
- Проделайте предыдущие шаги до пункта 4.
- Кликните в документе правой кнопкой мыши.
- В разделе «Параметры вставки» отыщите кнопку «Сохранить исходное форматирование». Наведите на неё — во всплывающей подсказке появится название. Если у вас компьютер с Office 2007, возможность выбрать этот параметр появляется только после вставки — рядом с добавленным фрагментом отобразится соответствующая пиктограмма.
Способ №1: копипаст
В некоторых случаях нельзя скопировать графику и форматирование. Только текст. Даже без разделения на абзацы. Но можно сделать скриншот или использовать специальное программное обеспечение для переноса содержимого страницы на компьютер.
Сайты с защитой от копирования
Иногда на ресурсе стоит так называемая «Защита от копирования». Она заключается в том, что текст на них нельзя выделить или перенести в другое место. Но это ограничение можно обойти. Вот как это сделать:
- Щёлкните правой кнопкой мыши в любом свободном месте страницы.
- Выберите «Исходный код» или «Просмотр кода».
- Откроется окно, в котором вся информация находится в html-тегах.
- Чтобы найти нужный кусок текста, нажмите Ctrl+F и в появившемся поле введите часть слова или предложения. Будет показан искомый отрывок, который можно выделять и копировать.
Если вы хотите сохранить на компьютер какой-то сайт целиком, не надо полностью удалять теги, чтобы осталась только полезная информация. Можете воспользоваться любым html-редактором. Подойдёт, например, FrontPage. Разбираться в веб-дизайне не требуется.
- Выделите весь html-код.
- Откройте редактор веб-страниц.
- Скопируйте туда этот код.
- Перейдите в режим просмотра, чтобы увидеть, как будет выглядеть копия.
- Перейдите в Файл — Сохранить как. Выберите тип файла (лучше оставить по умолчанию HTML), укажите путь к папке, где он будет находиться, и подтвердите действие. Он сохранится на электронную вычислительную машину.
Защита от копирования может быть привязана к какому-то js-скрипту. Чтобы отключить её, надо в браузере запретить выполнение JavaScript. Это можно сделать в настройках веб-обозревателя. Но из-за этого иногда сбиваются параметры всей страницы. Она будет отображаться неправильно или выдавать ошибку. Ведь там работает много различных скриптов, а не один, блокирующий выделение.
Если на сервисе есть подобная защита, лучше разобраться, как скопировать страницу ресурса глобальной сети другим способом. Например, можно создать скриншот.
Плюсы и минусы продвижения сателлитами
Преимущества продвижения с помощью сайтов-сателлитов очевидны:
- Удобный способ поддерживать качественную ссылочную массу
- Вы не зависите от рыночных цен на размещение ссылок
- Продвижение несколько проектов с помощью одной сети сателлитов
- Размещение рекламных блоков, покрывающих часть затрат на создание сети
- Есть возможность вытеснить конкурентов из выдачи по ключевым запросам
Недостатки такого метода продвижения:
- Высокая стоимость создания сети сателлитов, куда войдут регистрация домена и хостинга, подготовка контента
- Высокие временные затраты на создание сайта, разработку контента, продвижение
- Есть шанс попасть под пессимизацию Яндекс и Google при создании недостаточно трастовых ресурсов
Что такое бэкап сайта?
Бэкапом называют копию файлов, необходимых для работы сайта, а именно:
- Статических файлов – страниц, изображений, скриптов и т.п.;
- Динамических файлов – баз данных.
Где можно хранить резервную копию сайта?
- На личном компьютере, отдельном жестком диске, флешке или любом другом носителе информации;
- На сервере хостинга, услугами которого вы пользуетесь;
- В облачном хранилище.
Как правило, резервное (Бэкап) копирование данных делается силами хостинг-провайдеров, и все бекапы сайтов, хранятся на специальных серверах.
Важно четко понимать, какие именно данные вы сохраняете в резервной копии сайта (Бэкапа). Дело в том, что далеко не все организации проводят сразу полное копирование данных
Например, можно встретить ситуацию, когда статические файлы сохраняются в резервную копию раз в месяц, а базы данных, раз в неделю.
Такой подход чреват тем, что при восстановлении сайта из резервной (Бэкап) копии, часть элементов, взаимодействующих с базой данных, будет отсутствовать. Или наоборот, при взаимодействии с каким-то элементом, будет отправляться запрос в несуществующий раздел базы данных.
Поэтому, при резервном копировании сайта (Бэкап), лучше всего делать полную копию всех данных.
Важно понимать, что сам процесс копирования данных сайта, производится не моментально, и создает определенную нагрузку на сервер. Поэтому, рекомендуется делать бэкап в то время, когда взаимодействие с сайтом сведено до минимума, например, глубокой ночью
Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
Отключить JavaScript
2. Отключите JavaScript специальными расширениями для браузера (NOScript например) или вручную. С расширениями вы разберетесь, а вот про ручной метод расскажу подробней. И мне кажется это намного лучше, чем устанавливать лишний плагин.
Зайдите в настройки управления Google Chrome, перейдите в Настройки и внизу страницы кликните ссылку Показать дополнительные настройки. Здесь найдите раздел Личные данные и под этой надписью нажмите Настройки контента.

Здесь найдите раздел JavaScript, выберите Запретить выполнение JavaScript на всех сайтах и нажмите Готово. Обновите нужную вам страницу, и скопируйте текст без каких-либо помех. После этого вернитесь в эти настройки и верните все на свои места, чтобы остальные сайты правильно работали.

Если вы хотите навсегда отключить JavaScript у определенного сайта, зайдите в Настроить исключения. Введите адрес сайта в левое поле, а из выпадающего меню справа выберите Блокировать.

Теперь вы сможете в любой момент скопировать нужную информацию, без каких-либо проблем. Но имейте в виду, что после этого внешний вид сайта может измениться и некоторые функции перестанут работать.
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Где взять уникальный контент для сателлитов?
Оригинальный контент, пожалуй, один из важнейших параметров для хорошего сателлита. Несколько способом его получить:
Копирайтинг:
Самый простой и самый дорогостоящий метод. Необходимо создать техническое задание и отдать его SEO-копирайтеру, который напишет для вас уникальный, оптимизированный текст. Остается только разместить его.
Рерайт :
Более практичный способ получить уникальный материал для сайта. Рерайт – это переписывание уже созданного кем-то текста. В интернете размещено огромное количество контента. Качественный рерайт также, как и копирайтинг, даст вам уникальный, читабельный материал. Такой контент будет хорошо восприниматься и посетителями, и роботами поисковых систем.
Генерация текстов по шаблонам:
Можно назвать этот способ автоматическим рерайтом текста. Позволяет получить из одного материала множество новых. В этом вам помогут сервисы онлайн-генерации текстов. Например, Seogenerator. Принцип работы строится на использовании конструкций, которые заменяют фрагменты текущего текста на заданные варианты. Вот простой пример.
Задаем шаблон:
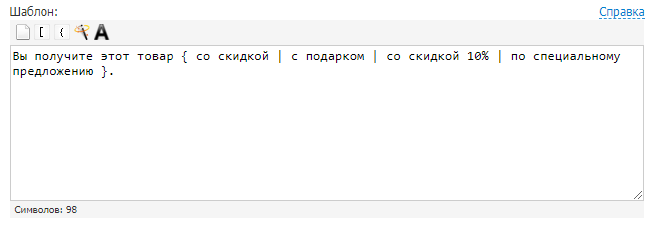
Получаем тексты:
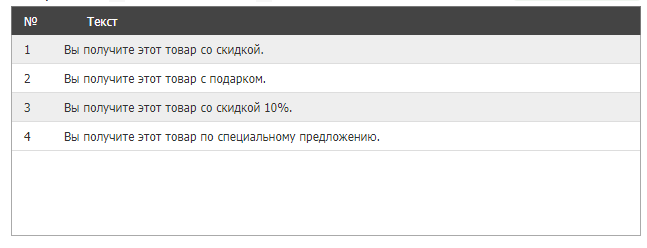
Важно следить за качеством, осмысленностью и уникальностью полученных материалов, объемные тексты проверять на возможный переспам. Вы формируете YML-выгрузку товаров
Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита
Вы формируете YML-выгрузку товаров. Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита.
Восстановление контента из веб-архива:
Ищем «дропы» – домены, у которых закончился срок регистрации – схожей тематики. Найти такие домены можно, например, с помощью Reg.ru. Проверяем историю, обратные ссылки, анкоры, не менялась ли тематика и т.д. Восстанавливаем нужный контент из веб-архива и получаем уникальный сайт. Для скачивания файлов из архива есть готовые сервисы, например, Archivarix. Все сайты имеют свои особенности, поэтому при восстановлении могут быть ошибки. Наш совет – заниматься восстановлением старых сайтов вместе с разработчиком.
Открыть в ворде
5. Откройте сайт в word – очень необычный способ, и потребуется немного времени, чтобы компьютер обработал запрос. Но зато вы получите полную копию страницы сайта в вордовском документе. Для этого в word нажмите Файл – Открыть – и введите ссылку на нужную страницу в поле Имя файла.

После этого нажмите Открыть и подождите. Скорость загрузки зависит от веса сайта, и производительности ПК. Лучше перед этим сохранить все открытые документы, чтобы в случае сбоя не потерять данные.
Не копируется текст с сайта – что делать?
Бывают случаи, когда статья отображается не в виде текста, а картинкой. Тогда вышеперечисленные способы не помогут скопировать информацию. В этом случае нужно скопировать картинку, если есть такая возможность – нажмите на ней ПКМ и выберите Сохранить картинку как…
Когда владелец сайта блокирует мышку, сделайте скриншот сайта. Для этого нажмите на клавиатуре PrintScreen и вставьте в графический редактор с помощью клавиш ctrl + v. Подойдет даже обычный Paint. Обрежьте все лишнее, чтобы остался только нужный текст.
Теперь найдите в интернете любой онлайн сервис для распознавания текста, и прогоните через него картинку. Через пару минут вы получите текстовую версию этой статьи.
Выбирайте любой из рассмотренных способов как скопировать текст с сайта который защищен от копирования. Лично я для постоянных сайтов использую метод с JavaScript, а для новых – метод с печатью. Никаких муторных методик, и не придется долго думать что же делать если не копируется текст с сайта.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
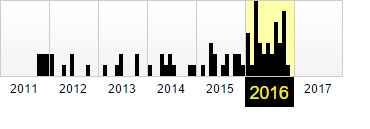 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.