Онлайн сервис восстановления сайтов из веб архива
Содержание:
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Проекты, предоставляющие историю сайта
 Peeep.us в действии
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Features
- Save Page Now — Instantly save the page you are currently viewing in the Wayback Machine. Turn on Auto Save Page in settings to save pages that have not previously been saved. Must be logged in to use.
- Oldest, Newest & Overview — View the first version of a page or the most recently saved in the Wayback Machine. Or view a calendar overview of all archived pages.
- Replace 404s, etc… — When an error occurs, automatically check if an archived copy is available. Checks against 4xx & 5xx HTTP error codes.
- Wayback Machine Count — Display count of snapshots of the current page stored in the Wayback Machine.
- Relevant Resources — View archived digitized books while visiting Amazon Books, research papers and books while visiting Wikipedia, and recommended TV News Clips while visiting news websites.
- Site Map & Word Cloud — Present a sunburst diagram for the domain you are currently viewing, or create a Word Cloud from the link’s anchor text of the page you are on.
Introduction
wayback is an open source java implementation of the
The Internet Archive
Wayback Machine.
The current production version of the Wayback Machine is implemented in
perl, and lacks in maintainability and extensibility. Also, the code is
not open source. Primary motivation for the new version is to address
these three issues, enabling public distribution of the application, and
easy experimentation with new features and access technologies.
The current Java version of the Wayback Machine supports three access,
or Replay modes of operation: «Archival Url» mode «Proxy» mode, and
«Domain Prefix» mode.
Archival URL mode provides a user experience very close to the current
production Wayback Machine. All query and replay access requests can be
expressed as URLs. In Archival Url replay mode, archived content is
modified as it is returned to users, attempting to make links and
embedded content refer back to the Wayback Machine by rewriting them as
Archival URLs.
Proxy URL mode allows replaying of archived documents within a client
browser by configuring the browser to proxy all HTTP requests through
the Wayback Machine. This has the strong advantage that no Javascript
or server side page markup is required to coerce the client browser to
request additional URLs and embedded content from the Wayback Machine
— content just works as-is. When used with the Firefox plugin
extension, available
here
, client browsers can navigate between versions of the current
document, and the Wayback Machine server will attempt to display images
from the same time period as pages being viewed. The Proxy URL mode
requires special configuration of the client web browser to access the
Wayback Service. This browser configuration is not complex, but it
means that content cannot be accessed as a global URL.
DomainPrefix mode is similar to ArchivalUrl mode, but uses a wildcard
DNS scheme to rewrite URLs, allowing all URL substitution to occur on
the server. This mode is considered experimental.
See the Administrator Manual
to learn more about access modes.
The current Java version can operate in several deployment modes,
ranging from a stand alone application on a single host holding all
archived documents and indexes, up to a highly distributed system where
indexes and archived content is spread across hundreds of machines.
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:

Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:

Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:

Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.

Долистал я до 23 октября 2017-го и вижу уже другое содержимое:

Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:

А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
IT-специалист и продвинутый пользователь ВК. Зарегистрировался в соцсети в 2007 году.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например,
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например,
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Wayback Machine Browser Extension
The Wayback Machine also has an official browser extension for Google Chrome. Using it to archive web pages is super easy. Simply navigate to a page you want to archive, click on the Wayback Machine icon in your toolbar and click “Save Page Now.”
In addition to making it even easier to save pages, the browser extension has another nifty trick up ts sleeve. Have you ever clicked on a link only to be confronted by a vague 404 error message? Whether it is a valuable source for your research paper or a really good recipe, it can be incredibly frustrating. With the Wayback Machine extension installed, that frustration could turn into a sigh of relief. When your browser runs into a dead end, the extension will search the archive to see if there is a saved copy on the Wayback Machine. If there is, it will ask you if you would like to visit that page.
If you don’t use Chrome, don’t fret. There is a Wayback Machine extension available for Firefox; however, it is still a work in progress. Additionally, there are plans to develop an extension for Safari users as well.
Top Websites Like Wayback Machine (Web Archive Sites)
1) Archive.fo
Archive.fo is online tool that helps you to create a copy of the webpage. This copy will remain online, even if the original page is removed.
Features:
- This application saves a text and a graphical copy of the page for better accuracy.
- It is one of the best Wayback Machine alternatives that gives a short link to an unalterable record of any web page.
- This tool allows you to track changes of the website containing job offer, price list, blog post, real estate listing, and so on.
- Saved pages do not contain any malware or popups.
Link: https://archive.fo/
2) Perma.cc
Features:
- You can delete links within 24 hours after creation.
- It helps you to view archived records through Perma.cc link
- URLs can be inserted via blog or paper articles.
- This Wayback Machine alternative enables you to create Parma that visits the website and create a record of the content of that website.
- If the preservation fails, this app will give you options to upload PDF file or image.
- Individuals can get access to permalinks via tiered subscriptions.
- You can assign users to any organization by simply submitting the user’s email address into this cloud-based program.
Link: https://perma.cc
3) Pagefreezer
PageFreezer is a SaaS service that provides blogs, websites, and social media archiving. It helps financial services firms and enterprises to capture online conversations, ensures to monitor risk.
Features:
- This online app validates the authenticity and integrity of your records.
- This Wayback Machine alternative can collect dynamic web content in real time.
- PageFreezer can capture internal social media networks.
- It can capture corporate chat conversations and monitor activity for potential risks.
- You can archive SMS or text messages.
- It helps you to collect and manage online content.
- You can access the past web on demand.
Link: https://www.pagefreezer.com
4) Actiance
Actiance app help organizations to capture and archive electronic communications. It is one of the sites like Wayback Machine which supports more than 80 channels.
Features:
- Capture all relevant communications.
- You can identify and manage risk and extract the business value of your data.
- It allows you to produce, package, and deliver content on-demand.
- This cloud-based app provides an analytics dashboard for better visualization of data.
- It is one of the best archive website that includes advanced as well as proximity search across all channels.
- It offers comprehensive and customizable reporting.
Link: https://www.smarsh.com
5) Stillio
Stillio is a tool that automatically captures website snapshots, archives and shares to other users. You can manage your website history and save lots of time.
Features:
- You can set screenshot frequencies according to your customized duration
- You can add multiple URL at once.
- You can save the screenshot to Dropbox.
- It supports URL sharing.
- It is one of the best Web Archive Sites which enables you to filter URLs by domain.
- You can use custom titles to keep everything organized.
- Stillio website time machine helps you to take a screenshot from the website geographic location by identifying it’s IP address.
- You can hide unwanted elements like overlays, banners, or cookie popups.
Link: https://www.stillio.com
6) UK Web Archive
UK Web Archive collects details of numerous sites each year and preserves for the future. It is one of the best Web Archive Sites that focuses on subject, event or areas of interest, and social media to archive.
Features:
- You can use this website to search for UK web archives.
- It allows you to discover the website on various themes and topics.
- This app collects images, videos, html pages, pdf, etc.
- It is one of the best Internet archive sites that performs automated collection of range of UK website in one year.
Link: https://www.webarchive.org.uk/ukwa/
7) Memento Time Travel
Memento time travel helps you to search and view versions of webpages that existed in the past. It is one of the best website archive sites that supports finding Mementos in web archives.
Features:
- It checks the whole range of servers to search web pages.
- This website displays web page components based on the time requested by you.
- It self-archives web server content.
- It focusses on various components like HTML, style sheets, and images, etc.
- You can see the distribution of archival DateTime using the timeline.
- This Internet time machine provides a bar chart showing checked and missing components.
Link: http://timetravel.mementoweb.org/
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
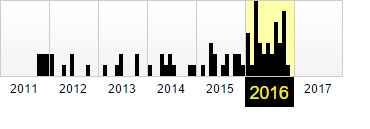 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
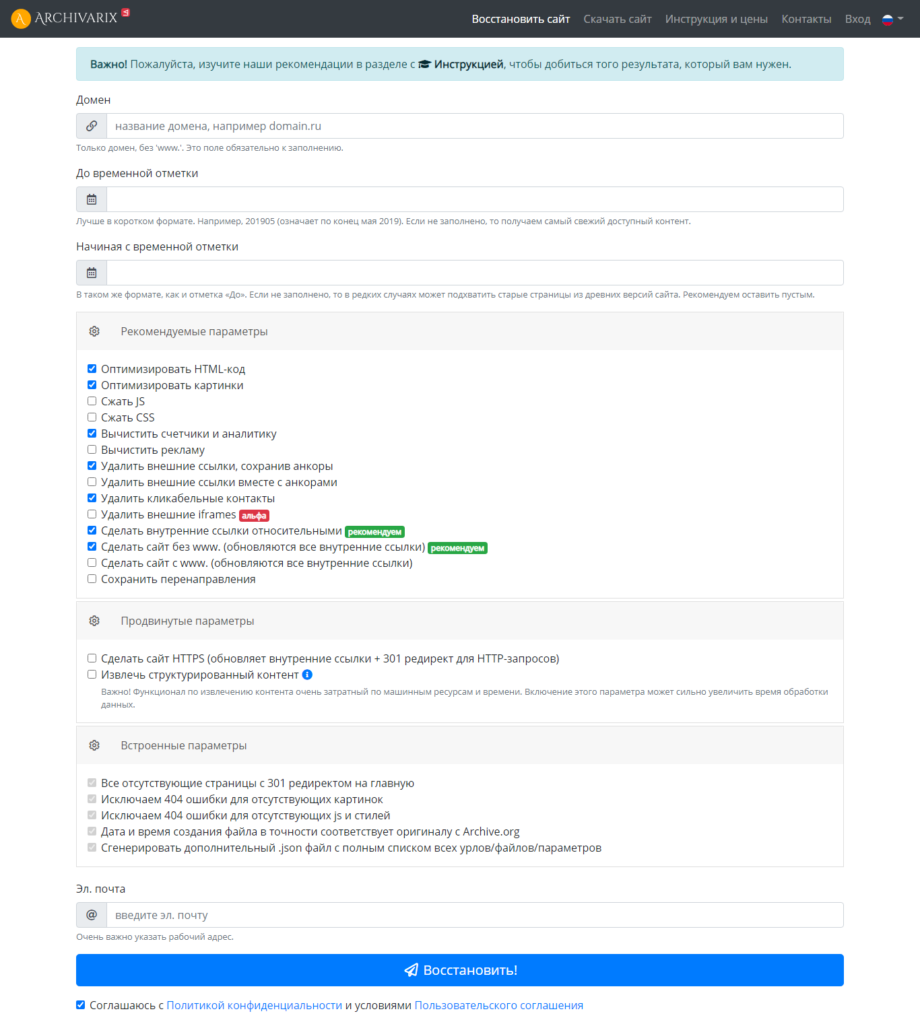
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
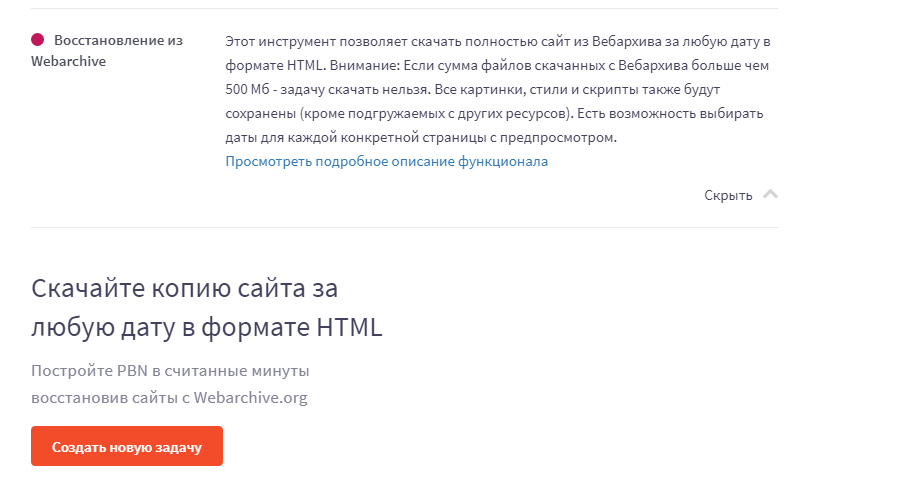
Ссылка на сервис https://www.rush-analytics.ru/land/skachivanie-kopiy-saytov-iz-wayback-machine
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
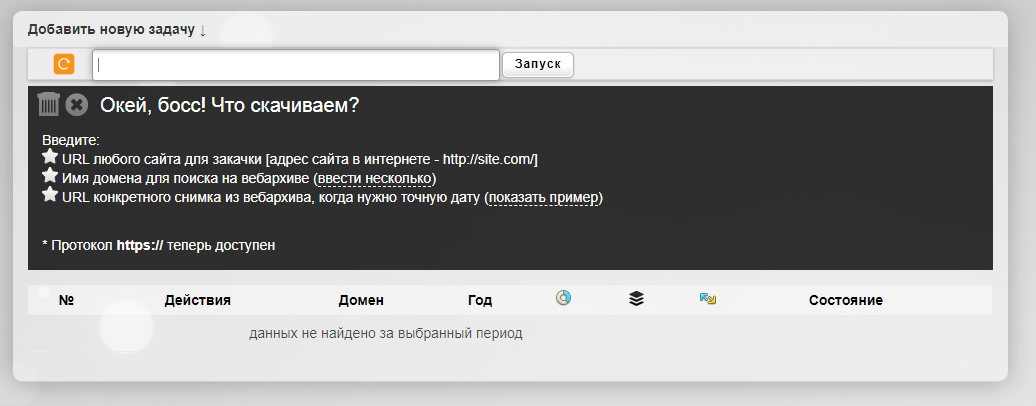
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.
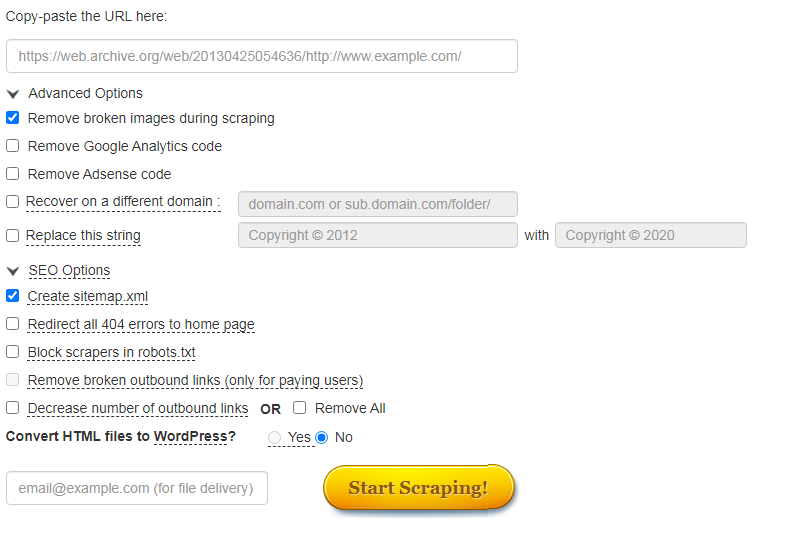
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
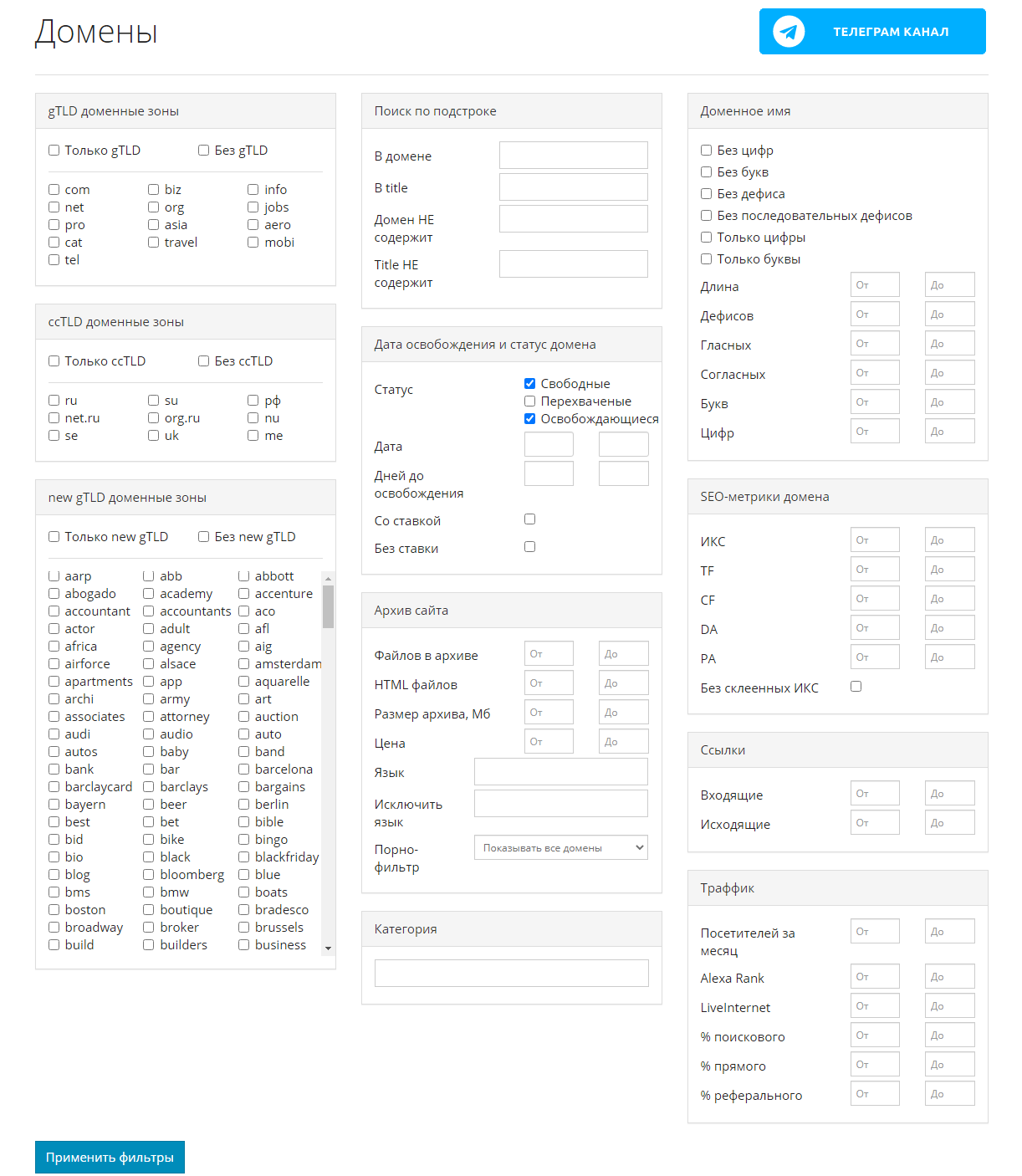
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.